How I led a Dynamic Data Engineering Team?

Picture credit: Unsplash
As humans we always remember the important events of our lives - the "Good" and the "Not so good". Our life journey is a tapestry woven together with colorful threads, each representing unique personal experiences. Have you ever compared the front and back of a tapestry? The front is colorful and pretty, and the back lacks clarity and detail. As we reflect back on our lives, we connect the dots of the life experiences that helped make that beautiful tapestry. In this paper, I would like to share a set of data engineering problems that my team experienced, and solutions that we devised as colorful threads in coherent and elegant whole.
As a leader of the Data Engineering team, I managed a group of data engineers, data analysts and architects who were responsible for supplying business stakeholders with the analytic insights that creates competitive advantages. The customer requirements, market opportunities and product evolution drove a series of questions.
The processes that worked like a charm a few years ago had to be re-engineered and modernized to drive faster business outcomes. I started noticing the data processes to drive the features moved slower, constrained by development cycles, limited resources and cross-functional dependencies. The gap between what the customer needed and the data acquisition from IT was often a source of conflict. Inevitably this mismatch between expectations and capabilities caused dissatisfaction preventing from fully realizing the strategic benefit of our data.
I will take you through my journey of overcoming obstacles by embracing hybrid Cloud environments, modern tools and technologies for digital transformation so we could reap the benefits of a solid, long-term solution. As we pivoted our focus on modern applications, modern infrastructure, and clouds to deliver better customer experience, reliability was the #1 goal and key focus areas were Availability, Performance, and Security. I drove initiatives for Big Data projects and Hybrid-Cloud transformation with focus on Distributed Data Sytems, Agile, DevOps, DataOps, Analytics, SecOps and Business Intelligence.
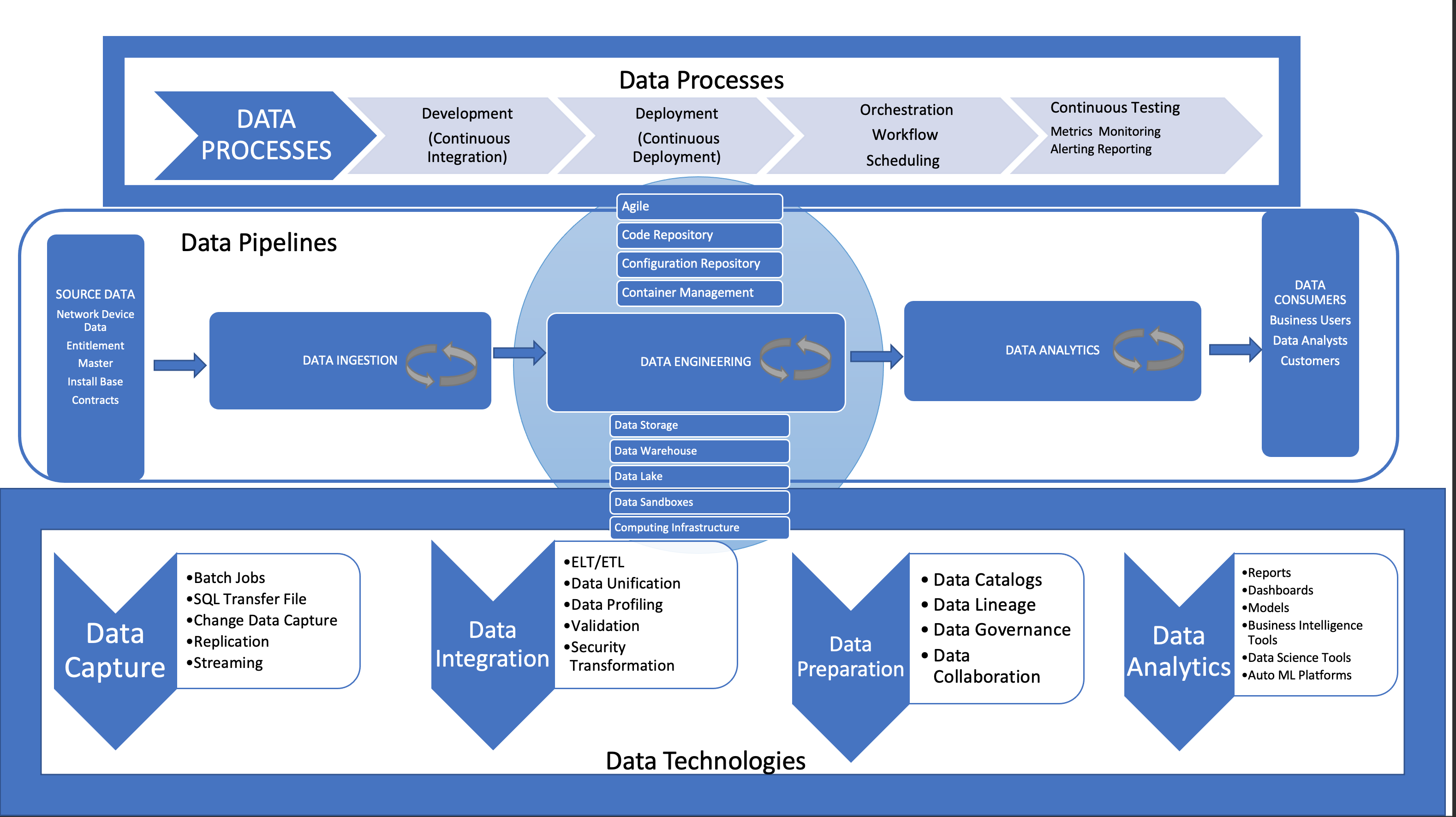
Figure: DataOps Components
The Problem
-
Requirements kept changing
- Users were not aware of the insights unless educated. They needed results ASAP.
- The requirements kept rolling in.
-
Many Silos
- Data was collected in separate databases which typically did not talk to each other
- Business stakeholders wanted fast answers. Meanwhile, the data team had to work with IT to gain access to intellectual data systems, plan and implement architectural changes, and further develop/test/deploy new insights.
- This process was complex, lengthy and subject to numerous bottlenecks and blockages
-
A Variety of Data Formats
- Data in operational systems is usually not structured in a way that lends itself to the efficient creation of analytics
- It’s also important for the schema of an analytics database to be easily understood by humans.
-
Data Errors
- Data errors could be caused by a new algorithm that didn't work as expected. i.e a database schema change that broke one of the feeds, an IT failure caused stale data.
- Data errors were difficult to trace and resolve quickly
- This caused unplanned work, which diverted your key contributors from the highest priority projects to work on bugs.
- If business colleagues repeatedly see bad data in analytics reports, it resulted in lack of trust or value the work product of the data-analytics team.
-
Data Pipeline Management
- Data pipeine is a process that executes a set of operations and attempts to produce a consistent output at a high level of quality. Every new or updated data source, schema enhancement, analytics improvement or other change triggered an update to the pipeline. The data team was continuously making changes and improvements to the data pipeline
- The effort required to validate and verify changes often took longer than the time required to create the changes in the first place. The analysts, data scientists and engineers spent a lot of their time updating, maintaining and assuring the quality of the data pipeline
-
Manual Processes
- Data integration, cleansing, transformation, quality assurance and deployment of new analytics must be performed flawlessly day in and day out. The data-analytics team may have automated a portion of these tasks, but some teams perform numerous manual processes on a regular basis. These procedures were error prone, time consuming and tedious.
- High-performing data team members handled repeated manual data procedures
The Solution
As we pivoted our focus on modern applications, modern infrastructure, and clouds to deliver better customer experience, reliability was #1 goal and key focus areas were Availability, Performance, and Security.
Agile, DevOps and DataOps methodologies impact productivity, quality and reliability in data analytics.
Let's take a moment to define DataOps, DevOps and Continuuos Delivery before we get into the specific details.
DataOps(The new normal) is a combination of tools and methods, which streamline the development of new analytics while ensuring data quality. DataOps helps shorten the cycle time for producing analytic value and innovation. My DataOps team is a collaborative and cross-functional analytics team that values analytics that work; we measure the performance of data analytics by the insights we deliver. DataOps team embraces change, and seeks to constantly understand evolving customer needs.
DevOps(The new normal) improves collaboration between employees from the planning through the deployment phases of software. It seeks to reduce time to deployment, decrease time to market, minimize defects, and shorten the time required to fix problems. The DevOps approach brings together software development and operations to more closely align development with business objectives and to shorten development cycles and increase deployment frequency.
Continuous delivery(The new normal) requires automation from planning all the way through to delivery/deployment. Previously, software development, testing, quality assurance, and customers could each be running in different environments. This hampered their ability to communicate and led to misunderstandings. I also included Continuous Tuning and Continuous Cost Optimization(Tuning our Infrastructure-as-a-code script, reviewing TCO)

Figure: Grow your leadership flame
What did our software development pipeline look like?
The software development pipeline has these steps: Planning, resourcing, development, testing, quality assurance, and deployment.
What were the key business benefits of adopting DataOps?
Adoption of Dataops helped reduce time to produce insights and improved quality of the data analytics processes. The opportunities to ask the next business question were easier that lowered the marginal cost. The biggest benefit was it boosted team morale by becoming more data driven in decision making. Finally, we achieved greater team efficiency by following agile processes, reuse and refactoring. We were handling change successfully and went beyond data engineering to preserve the value of our data.
Why did we accelerate our Cloud Adoption?
We wanted to accelerate the Cloud adoption because we were trying to respond to new customer demands spikes and offer SaaS services to our customers in an agile way.
What did we do to continuously deploy new functionality during Cloud migration?
There is a renewed focus on reliability, scalability, and performance of systems that are generating revenue. The CI/CD paired with "Observability" is the new evolutionary step in delivering new functionality while keeping up with reliability. Observability is a property of the system and application that enables an external observer to monitor and troubleshoot and be able to understand what's happening to that application in real time even if the conditions that caused it were previously unknown. I would recommend Datadog, Elastic, Sumo Logic, and Weavescope.
How did we do things differently?
We re architected backend distrubed systems and built a flexible stack that will keep working for the business as it evolves. We made a shift from on-premise private data center to AWS Cloud. We are dealing with a whole different operating model, and the shift is in managing these cloud and on-premise workloads in an orchestrated way. Our organization has adopted new methodologies, new processes, new tools, new skill sets, and teams have to be recombined into different types of teams—cross-functional teams—because cloud environments are ever-changing. The cloud enables scale with hardware and agile development delivered rapid evolution and change of software i.e our applications.
How did we measure that we are on track?
The platform capabilities i.e. observability and reliability are integrated end to end. Discipline started with a software delivery process i.e. development and CI/CD [continuous integration/continuous development] pipeline. The development and system observability kept track of all the KPIs related to deployments frequency, history, production changes(successful/failed/rolled back) and how quickly we are able to recover from those failures.
What is our approach for Hybrid and Multi-cloud operations management?
We had adopted Kubernetes 5 years ago along with microservices based applications. The modernization of our development stack allowed us to pivot to AWS fairly quickly. I expect to see continuous acceleration in cloud adoption journey of multiple clouds continued with Kubernetes, microservices-based API and service meshes. With modern methodologies like Agile, DevOps, DataOps and Observability to deliver reliable, secure, and performant applications, we are in great shape to scale in production.
What is our approach for Security?
As we manage reliability we have strengthened SecOps (security across). The logs/metrics/traces data that helps with reliable performance and availability is also used to build secure applications. This cross-functional and streamlined approach to tooling, as well as to processes, has helped us deliver and continuously tune our applications to deliver more actionable and valuable insights.
What were the data formats we dealt with?
The network data comes in structured, unstructured and semi-structured formats. Depending on the use case the data was stored in relational databases (Oracle, MySQL, Aurora Serverless), data warehouse(Teradata, Snowflake), data lake(Snowflake, S3, MapR, distributed NoSql clusters(Cassandra, MongoDB, search/anaytics(Elasticsearch and S3 object store.
I have a written a detailed Blog - File Formats that discusses the data format options.
Data formats: csv, json, avro, parquet, orc, protobuf, arrow
What are the ways of data acquisition/ingestion?
- Real Time: Continuous ingestion of data in motion emitted by controllers, sensors, network management applications and devices under 100 milliseconds.
- Near Real-time: This is considered to be “immediately actionable” by the recipient of the information, with data delivered in less than 2 minutes but greater than 2 seconds.
- Change Data Capture: Reliable, sequenced, consistent and continuous change capture streams from transactional data stores and network event logs with minimal process overhead.
- Micro-batch: This is normally something that is fired off every 2 minutes or so, but no more than 15 minutes in total.
- Macro-batch: This is normally anything over 15 minutes to hours, or even a daily job.
- Incremental Updates: This in theory is similar to change capture with the only difference being that the data is ingested periodically based on a schedule.
- Bulk Uploads and Large Files: This is typically for situations where we have an infrequent request/need to ingest data that is in the order of 100GBs or ingestion of syslogs or network logs in response to a API request.
In addition, asynchronous data ingestion of large datasets such as syslogs and case attachments add business context to the network data captured in a continuous stream. Different data consumers have different goals. The product teams have different analytics needs than Support, Operations or DevOps, not to mention Marketing and Business Intelligence. This usually leads to hybrid data management systems consisting of different technologies as no single solution can meet the needs of the business objectives. The need to support such diverse and disparate data sources and access mechanisms to support a wide variety of use cases presents a variety of challenges for an effective and robust data ingestion strategy. To a large degree the mechanism to use for data ingestion will be determined by the use case and the velocity of the data.
What approaches did we take for schema creation?
Schema-on-write, helps to execute the query faster because the data is already loaded in a strict format and you can easily find the desired data. However, this requires much more preliminary preparation and continuous transformation of incoming data, and the cost of making changes to the schema is high and should be avoided.
Schema-on-read, it has fast data ingestion because data shouldn't follow any internal schema — it's just copying/moving files. This type of data handling is more flexible in case of big data, unstructured data, or frequent schema changes. Schema-on-read, on the other hand, can provide flexibility, scalability, and prevent some human mistakes. It is generally recommended that data is stored in the original raw format (just in case) and optimized in another format suitable for further data processing. The ETL may have invalid transformations, and the original raw data will allow you to return to the original data and process it correctly. In addition, since the schema must be defined when querying data, SQL queries tend to be very complex. They take time to write, and even more to complete.
What was the data domain?
- Customer data - Account details, Organization, Entitlement - product coverage, solution eligibilty, License, Level of service
- Services data - Case - details, metadata, notes, attachments, bugs, and survey
- Installed Base, RMA, Contract etc
- Network data - Inventory, collection metadata
- Device data - Telemetry, syslogs, configs, CL, crash data, BDB scan results
- Insights data/capabilities - Actionable insights, suggested software, features enabled
- Product data(assets & coverage) - Features, Software End-of-life, Hardware End-of-life, Advisories, Field Notices, Bugs, Release date, product family, product ID, support data
- Administration data - Site roles, Organization mappings, registration, policy defintions, etc
Why did we switch from RDS to NoSQL distributed database?
We used Oracle primarily for all workloads. The performance requirements and SLA drove the re-architecture. We switched to horizontally-scalable multi-region Cassandra implementation for all of our core services. Oracle can achieve what you want, but in a roundabout way. It allows for no-downtime expansion of a cluster, but uses complex coordination mechanisms and special processes like Dynamic Database Services to achieve this. In Cassandra, this is simply a matter of adding a node, which is a foundational operation that doesn’t require special coordination or a service like Dynamic Database Services. The ability to scale linearly is built into the core of the technology
-
The design decisions behind Cassandra enable the advantages from Oracle above. Instead of trying to outfit an existing technology that was designed for a different purpose. Cassandra is designed specifically to achieve the functionality that modern applications require. Also consider the Disk architecture. RAC uses a shared disk architecture, which requires mechanisms for management and orchestration to avoid loss of data and maintain service availability. In Cassandra, by sharing no resources (a fundamental component of the architecture, not a feature), you completely bypass this problem and never even attempt to use shared disks, which are an anti pattern for truly distributed workloads.
-
Furthermore, at a certain scale, Oracle RAC deployments start to look more and more like Cassandra. Scaling an Oracle system requires simplification of models which takes away benefits of relational abstraction and de-normalization which takes away consistency. It also requires async replication across regions to avoid latency. It’s almost as if you are trying to make the Oracle system look more like the Cassandra system under the hood. If you start adding in the complexity that allows Oracle to do much more than Cassandra (at least functionally) you start introducing elements that hinder scale and availability, so you have to drop that RDBMS functionality in favor of scale and ability, negating the Oracle benefits entirely. For example, you can’t randomly access any data using a join if you want to have predictable performance. So in Oracle you denormalize to avoid joins. Why not just denormalize and use Cassandra, which has better built-in mechanisms for distribution?
-
In Oracle availability is a process of recovering from catastrophic failures. This is because of the coordination involved and the consistency guarantees that an ACID database provides. But because of these guarantees, users are looking at a failover process. And however fast RAC can recover, it’s still a fundamentally flawed architecture. Cassandra’s shared nothing architecture allows for complete disaster avoidance, not just disaster recover.
-
In a nutshell, Oracle is better for RDBMS use cases, But trying to use it for big data systems is only a solution until you can get a better NoSQL strategy in place with a true distributed system like Cassandra. Otherwise you will have to deal with rising costs and complexity. While Oracle RAC does it’s best to hide complexity required to backend modern applications, Cassandra doesn’t need to hide it’s complexity, as the functionality directly maps to goals of your system.
How did we plan for production readiness of a distributed system?
Monitoring system performance, understanding query access patterns and continuous tuning enabled us to be ready for production in 3 months.
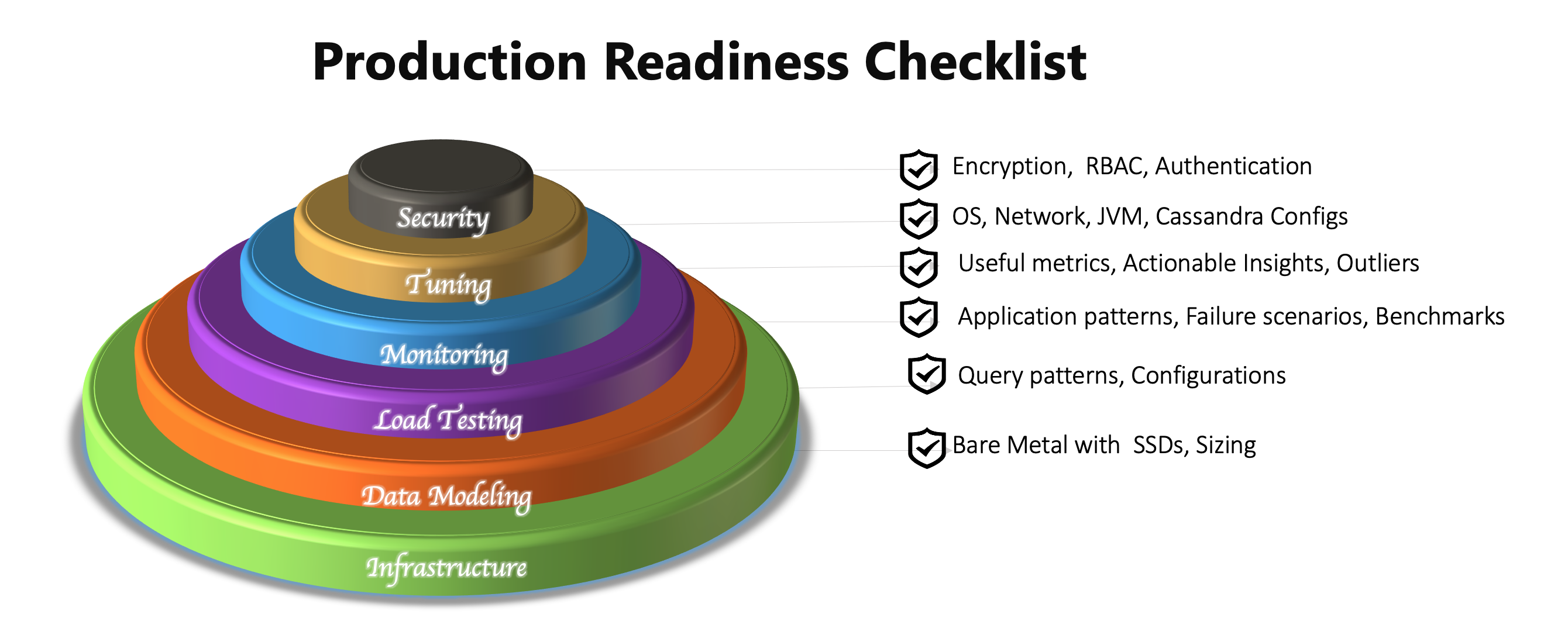
The Elasticseach-Logstash-Kibana log analytics opens up insights to view and correlate events that can lead to system slowness, corruption or even a system failure. Just to name a few top events from our list:
- Large batch warnings
- Tombstone warnings
- Excessive GC and/or long pauses
- Memtable Flush Writers warnings
- Compaction warnings and errors
- Connection failures
- Unwanted data access
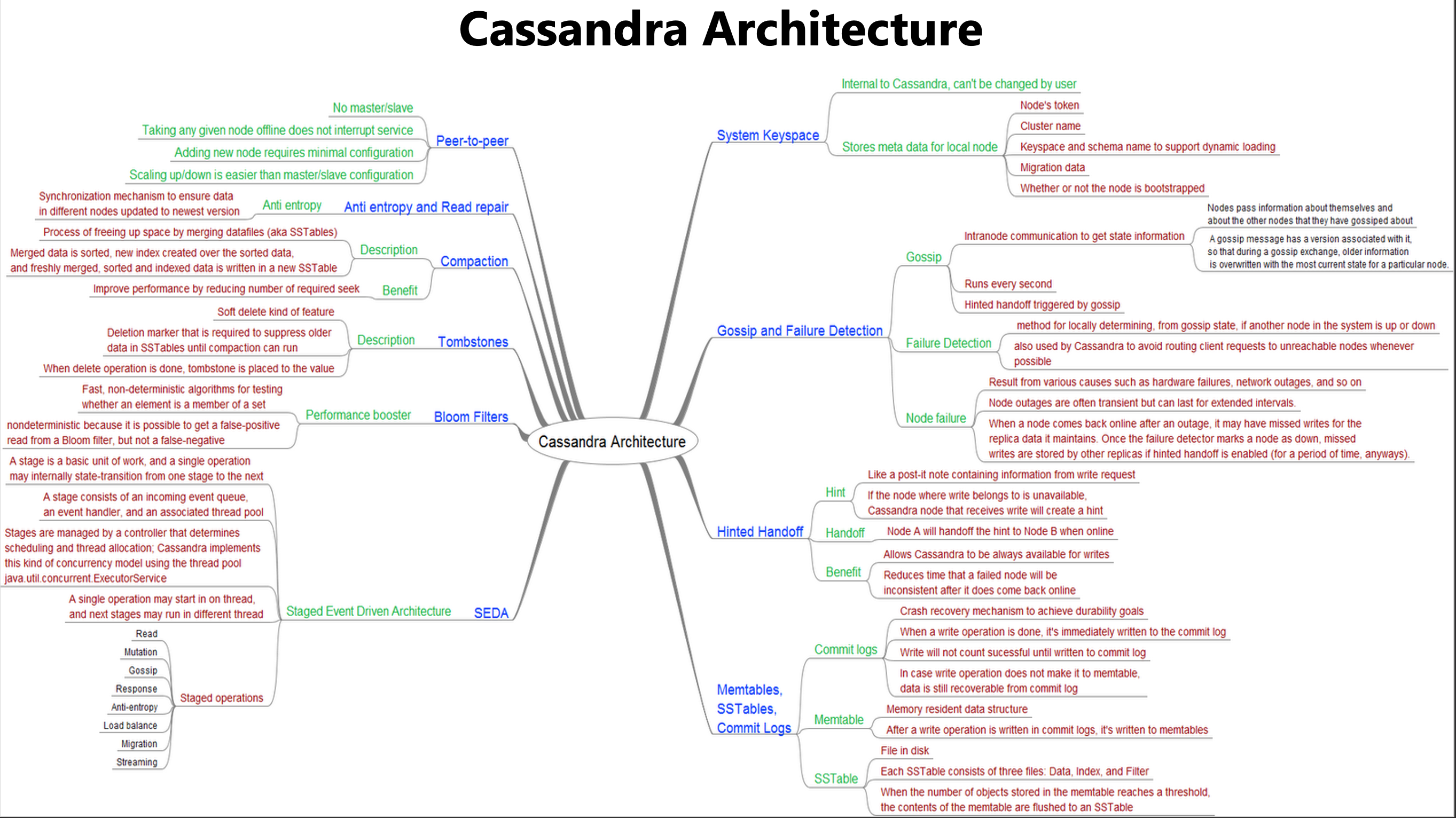
What was the best approach to switch to Cassandra?
Switching to Cassandra could be a daunting task if you are migrating your production workloads to multiple regions in Cloud and On-Premises. Start with a small cluster in single region, test your application to ensure the model is working correctly, setup our first Observability cluster i.e ELK or Graphana/Prometheus and webhooks to get notifications. Finally, I found this mindmap to be a great tool to demystify Cassandra.
What were the reliability tradeoffs?
Redundancy has a cost and a reliable system has to pay that to achieve such resilience for services by eliminating every single point of failure. Reliability is availability over time considering the full range of possible real-world conditions that can occur. At a high level, we chose to have the following policies in place:
- Backup and disaster recovery
- Consistency ( Read consistency and Write Consistency - Quorum)
- Look back to analyze failures, create goals and key metrics, build a reliability plan and put the reliability plan to the work. Tools: Gremlin
How did we harden our Kubernetes environment?
Have an observability plan for Kubernetes metrics to report on and track in real-time:
Number of Kubernetes clusters
Number of nodes
Number of nodes by cluster
Number of pods
Number of pods by node
Nodes by uptime (min to max)
Pods by uptime (min to max)
Number of applications/services
Number of applications/services by cluster
Resource utilization by node (e.g. CPU)
Disk writes per node
Disk reads per node
Network errors per node
Final thoughts
When we embarked on our transformation journey, there were numerous challenges. There were time-consuming and tedious challenges of mapping database schemas and application interdependencies to have a successful migration to Cloud. A hybrid framework enabled smooth testing and migration process, allowing us to work with disparate data sources and applications that co-existed, no matter where they were hosted. We were able to increase developer velocity, enable security at every step, automate every workflow, and redefined collaboration by using the right set of tools. We are able to reap the benefits of a Hybrid cloud environment (Openstack Private Cloud & AWS Cloud). The data and insights become more critical with growing business needs, transitioning allowed us realtime access to the entire data eco-system and derive real-time insights. We were able to frequently adjust to data strategies to ensure we are aligned with regulatory and compliance requirements. The new hybrid environment allowed us to unify and effectively utilize data that is most useful to real-time insights, decsion making, trendspotting and analytics needs.
With a solid plan for CI/CD and modernized tools like CircleCI, Flux, Jira Project Management Tool,Git Hub Enterprise to increase developer velocity, Confluence, Webex Teams and Observability Tools(mentioned above), we were able to accelerate and successfully complete the Cloud migration.
AWS Cloud gave us wings to complete the data migration project using DMS and powerful purpose built databases for our use cases. I will be writing another paper to share my experience with CDC from Cassandra to AWS(S3 and Aurora-MySQL).
The problems with frequent changes, silos, errors, pipeline management and velocity went away with automation, observability, decentralization of databases, S3 based data lake, managed services like ECS, serverless Lambda, Aurora, Elastic, SQS and Kinesis. So the journey continues and as I work through solving more complex challenges, I will continue to share my solutions and experiences with you.
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Kafka here
🔗 Read more about Spark here
🔗 Read more about Data Lakes Part 1here
🔗 Read more about Data Lakes Part 2here
🔗 Read more about Data Lakes Part 3here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here