Getting Started with Data Lakes (Part 3)

Data Security and Data Cataloging for data lakes
Table of Contents
Design Security 🚔
There are three primary domains of security relevant to a data lake deployment:
- Encryption
- Network Level Security
- Access Control
Data Security
New data privacy mandates such as EU's GDPR as well as the California Consumer Privacy Act (CCPA) which just took effect at the beginning of 2020, have increased the need to guard data, specifically personally identifiable information (PII). The growth of cloud data lakes presents new challenges when it comes to protecting personal data. With databases, sensitive data can be protected by enforcing permissions on the table, row and column level - as long as we know where which tables contain sensitive information, it was relatively straightforward to create a data governance strategy that prevents this data from reaching unauthorized hands.
However, with data lakes things are a bit trickier since you are now responsible for raw data in files rather than tables with known metadata. When data stored in unstructured object stores such Amazon S3, Google Cloud Storage and Azure Blob Store, it is very difficult to pinpoint the location of sensitive data in order to create an effective permissions policy. This business challengecan be solved using S3 partitioning and tokenization.
🦋 Tokenization is often used to protect credit card numbers or other sensitive information in payment processing systems, customer service databases, and other structured data environments. However, length-and-format-preserving encryption can address the same use cases, often with less complexity.
Establish Governance
Data governance refers to the overall management of the availability, usability, integrity, and security of the data employed in an enterprise. It relies on both business policies and technical practices. Similar to other described aspects of any cloud deployment, data governance for an enterprise data lake needs to be driven by, and consistent with, overarching practices and policies for the organization at large.
Enable Metadata Cataloging and Search
Data lakes contain a massive number of data sets with field names that are often cryptic, and some of the data sets are delimited files or unstructured data collected from online comments—may lack header lines all together. Even well-labeled data sets may follow a different naming conventions. It is non-trivial to guess what particular attributes may be called in different files, and thus impossible to find all instances of those attributes. As a result, data needs either to be documented as new data sets are ingested or created in the lake or to go through extensive manual examination, neither alternative being scalable or manageable for the typical size and variety found in big data systems.
Data catalogs solve the problem by tagging fields and data sets with consistent business terms and provide a user interface that allows the users to find data sets by using the business terms that they are used to, and to understand the data in those data sets through tags and descriptions that use business terms.
Utilize a data catalog to provide the discoverability and exploration of data sources and reports across the enterprise with:
-
Metadata
To help describe the data sets, we turn to metadata, or data about data. For example, in a relational database, a table definition specifies the metadata, including the table name, column names, descriptions, data types, lengths etc.
Technical Metadata
Studying each table to understand what it contains significantly slows down the process of finding the right table to use, profiling is often used to bridge the gap between data and metadata. Profiling analyzes the data in each column to help round out our understanding of the data as well as its quality and calculates - Cardinality, Selectivity, Density, Range, mean, and standard deviation and Format frequencies. The statistical information captured by profiling, together with other metadata such as the names of fields, tables, and files, is called technical metadata. While this helps us to understand the nature of the data, it does not address the problem of findability.
Profiling information for hierarchical data such as JSON or XML files is trickier. While the format may be different, conceptually JSON files represent the same data as tabular files. The same information may be presented in JSON format, with the hierarchy representing the relationships expressed by primary and foreign keys in relational systems. Instead of many different tables, a single JSON file will capture all the attributes and relationships. A simple process called shredding is often used to extract fields from hierarchical files. Shredding basically creates a unique field for each unique XPATH expression in a hierarchical file. One problem with shredding is that it is what’s called “lossy”, as it loses information when transforming the data into tabular format.
Profiling tools such as Lumada Data Catalog were developed for nonrelational big data environments either profile hierarchical data natively in a nonlossy way or at least shred hierarchical data automatically.
Business Metadata
To help analysts find data, business metadata, or business level descriptions of the data are used. Business metadata is often captured in glossaries, taxonomies, and ontologies.ontology is generally more elaborate than a taxonomy and supports arbitrary relationships between objects. For example, in addition to relationships, it includes relationships between objects and attributes. Folksonomies are much less rigorous constructs that attempt to represent how employees think of their data. Instead of training analysts to use strict definitions, folksonomies collect current terms, organize them into coherent hierarchies, and use them as business metadata.
-
Data Tagging
Once we have a glossary, taxonomy, folksonomy, or ontology, in order to use it to find data sets, we have to assign the appropriate terms and concepts to those data sets. This process, known as tagging, consists of associating business terms with the fields or data sets that contain the data represented by those terms. Although manual tagging and crowdsourcing are necessary, usually these processes are not sufficient and time consuming. the answer to this problem is automation.
New tools leverage AI and machine learning to enable identification and automatic tagging and annotation of elements in dark data sets (based on tags provided elsewhere by SMEs and analysts), so that analysts can find and use these data sets. Automatically tags fields based on field names (if available), field content, and field context. automated cataloging. An example of such a tool is "Aristotle - Waterline Data’s AI driven classification engine" . It crawls through Hadoop clusters and relational databases and fingerprints every field (a fingerprint is a collection of the field’s properties, including its name, content, and profile). It then lets analysts tag the fields while they are working with different files and tables.
Fingerprint works across three dimensions:
- Content (the actual values and their characteristics)
- Metadata (names, comments, etc.)
- Context (for example, a field containing numbers between one and six digits and no NULLs in a record with street names, city names and zip codes is very likely a house number; a record without any other address components is very unlikely to be a house number).
The regulations govern usage and protection of personal or sensitive information, such as the GDPR in Europe, HIPAA in the US, and PCI internationally. In addition, companies often maintain their own lists of internal sensitive information that must be protected. Any data that is subject to regulatory compliance and access restrictions as sensitive. To manage sensitive data, enterprises have to first catalog it (i.e., find out where it is stored) and then protect it, through either restricting access or masking the data.
Two important innovations that a catalog brings are the ability to apply tag based data quality rules and to measure the annotation quality and curation quality of a data set.
Data set quality includes: tag based data quality, annotation quality, and curation quality. The approaches range from only considering the quality of curated tags to trying to reflect every aspect of data quality.
-
Data Classification
The challenge of finding data then becomes not only to find the data sets that contain the data you need, but to be able to tell if these data sets can be combined. Can these data sets be joined? Will joins produce meaningful results?
In order to be useful, catalogs should assist users in finding related data and estimating the usefulness of combining it. There are several ways that can be achieved: Field names, Primary and foreign keys, Usage (ETL jobs, Database views, reports, SQL queries), and Tags.
An automated approach is required to complete this classification. Tools allow analysts to tag data in some fashion an automated discovery engine that learns from analyst tagging and automatically classifies other data sets.
Deciding on data formats is a choice and considerations include:
- Compatibility with upstream or downstream systems
- File sizes and compression levels
- Data types supported
- Handling of schema changes over time
- If a self-describing schema is desired
- Convenience, ease of use, human readability
When organizing the data within the raw and curated zones, focus on considerations such as:
- Security boundaries
- Time partitioning
- Subject area
- Confidentiality level
- Probability of data access (i.e. hot vs. cold data)
- Data retention policy
- Owner/steward/subject matter expert
-
Data Lineage
There really isn’t one single way to get all the lineage, but the catalog is responsible for importing this information from wherever possible and stitching it all together. “Data Stitching” refers to the process of connecting different lineage segments.
In this example, a table may have been ingested from an Oracle data warehouse using Informatica’s ETL tool into a data lake file in Parquet format. This data is then joined with a JSON file generated from a Twitter feed using a Python script to create a new Hive table. Later hive table was used by a data prep tool to create a CSV file that was loaded into a table in a data mart. The table in the Data Mart is used by a BI tool to generate a dashboard report. To get an end-to-end picture of where the data in the report came from, all these steps need to be stitched together to tie the report back to the original sources—the Oracle data warehouse and Twitter feed.
In a data pipeline, data undergoes many changes by many tools. The lineage is available, but it is federated and expressed in the language of the tool that generated the data. To be able to interpret the data stages, the analyst needs the steps documented in business terms. This is called Business Lineage. The truth is, most enterprises today do not have a place to capture and track business lineage. Each job and step may be documented, but this is often done inside the tool (for example, as comments in a script), or in the developers’ notebooks, Excel files, or wikis. Catalogs gather such lineage documentation by stiching data lineage segments together and make it available to the users of the data.
One tip is to include data lineage and relevant metadata within the actual data itself whenever possible. For instance: columns indicating the source system where the data originated.

🏬 A separate storage layer is required to house cataloging metadata that represents technical and business meaning. While organizations sometimes simply accumulate contents in a data lake without a metadata layer, this is a recipe certain to create an unmanageable data swamp instead of a useful data lake.
Enforce a metadata requirement ㊎ Ensure that all methods through which data arrives in the core data lake layer enforce the metadata creation requirement, and that any new data ingestion routines must specify how the meta-data creation requirement will be enforced.
Automate metadata creation 🚗 Like nearly everything on the cloud, automation is the key to consistency and accuracy. Wherever possible, design for automatic metadata creation extracted from source material.
Prioritize cloud-native solutions ⛅️ Use cloud-native automation frameworks to capture, store and access metadata within your data lake.
An AWS-Based Solution Idea 💡 An example of a simple solution has been suggested by AWS, which involves triggering an AWS Lambda function when a data object is created on S3, and which stores data attributes into a DynamoDB data-base. The resultant DynamoDB-based data catalog can be indexed by Elasticsearch, allowing a full-text search to be performed by business users.
AWS Glue provides a set of automated tools to support data source cataloging capability. AWS Glue can crawl data sources and construct a data catalog using pre-built classifiers for many popular source formats and data types, including JSON, CSV, Parquet, and more. As such, this offers potential promise for enterprise implementations.
💁♂️ Data cataloging must be a central requirement for a data lake implementation.
Access and Mine the Lake 🐠
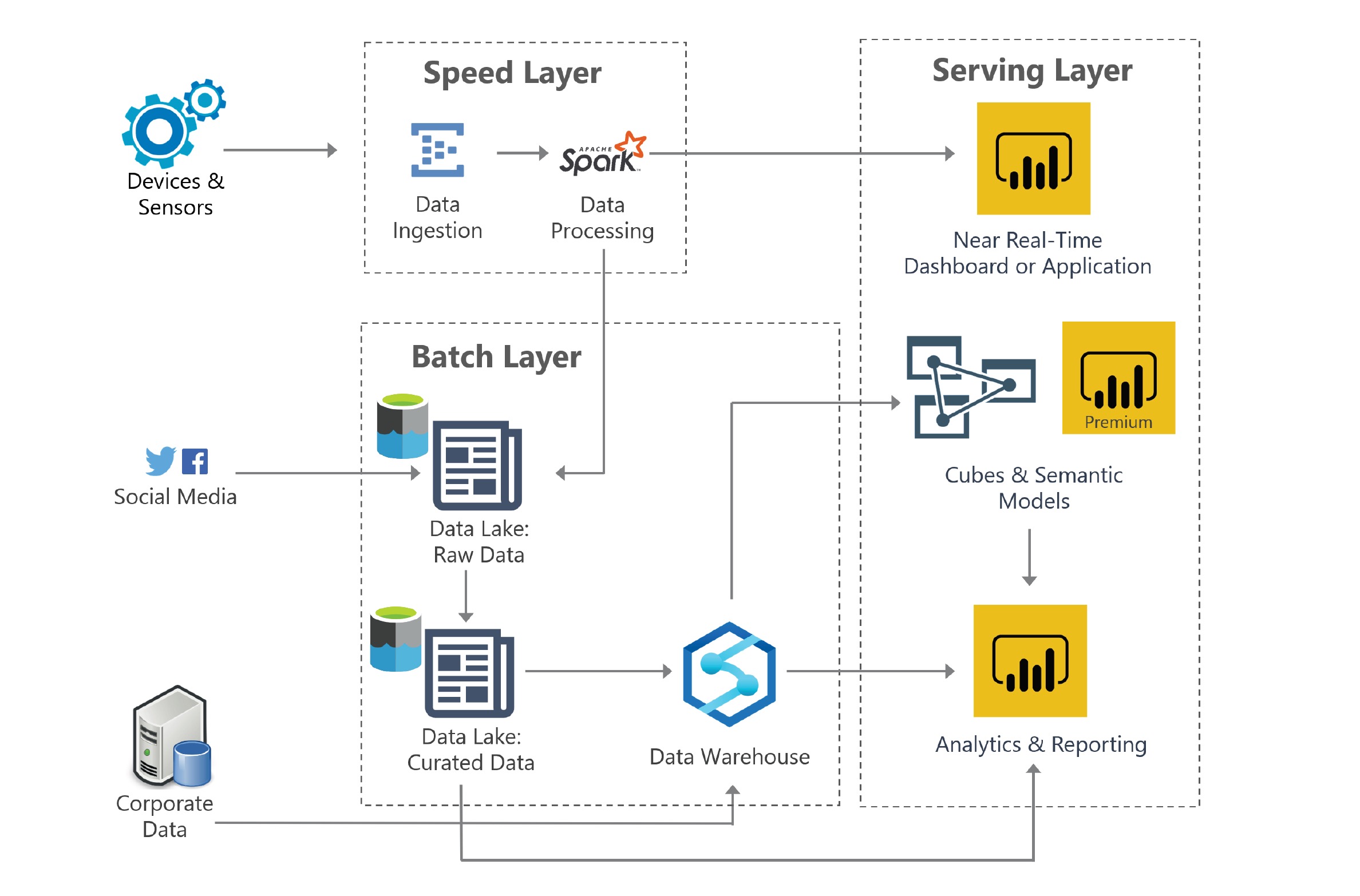
Schema on Read
‘Schema on write’ is the tried and tested pattern of cleansing, transforming and adding a logical schema to the data before it is stored in a ‘structured’ relational database. However, as noted previously, data lakes are built on a completely different pattern of ‘schema on read’ that prevents the primary data store from being locked into a predetermined schema. Data is stored in a raw or only mildly processed format, and each analysis tool can impose on the dataset a business meaning that is appropriate to the analysis context. There are many benefits to this approach, including enabling various tools to access the data for various purposes.
Data Processing Typical operations required to create these structured data stores will involve:
- Combining different datasets
- Denormalization
- Cleansing, deduplication, householding
- Deriving computed data fields Apache Spark has become the leading tool of choice for processing the raw data layer to create various value-added, structured data layers.
Data Warehousing 🏘 For some specialized use cases (think high performance data warehouses), you may need to run SQL queries on petabytes of data and return complex analytical results very quickly. In those cases, you may need to ingest a portion of your data from your lake into a column store platform. Examples of tools to accomplish this would be Google BigQuery, Amazon Redshift or Azure SQL Data Warehouse.
Interactive Query and Reporting ❓ There are still a large number of use cases that require support for regular SQL query tools to analyze these massive data stores. Apache Hive, Apache Presto, Amazon Athena, and Impala are all specifically developed to support these use cases by creating or utilizing a SQL-friendly schema on top of the raw data.
Data Exploration and Machine Learning Finally, a category of users who are among the biggest beneficiaries of the data lake are your data scientists, who now can have access to enterprise-wide data, unfettered by various schemas, and who can then explore and mine the data for high-value business insights. Many data scientists tools are either based on or can work alongside Hadoop-based platforms that access the data lake.
Summary
In the part-4 of this series we will go over the final consideration and thoughts to help us getting started with our data lake journey.
Credits
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Kafka here
🔗 Read more about Spark here
🔗 Read more about Data Lakes Part 1here
🔗 Read more about Data Lakes Part 3here
🔗 Read more about Data Lakes Part 4here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here