Getting Started with Data Lakes (Part 2)

Table of Contents
Sample Architecture for creating a Data Pipeline
The architecture diagram below depicts the components and the data flow needed for a event-driven batch analytics system. At a high-level, this architecture approach leverages Amazon S3 for storing source, intermediate, and final output data; AWS Lambda for intermediate file level ETL and state management; Amazon RDS as the state persistent store; Amazon EMR for aggregated ETL (heavy lifting, consolidated transformation, and loading engine); and Amazon Redshift as the data warehouse hosting data needed for reporting.
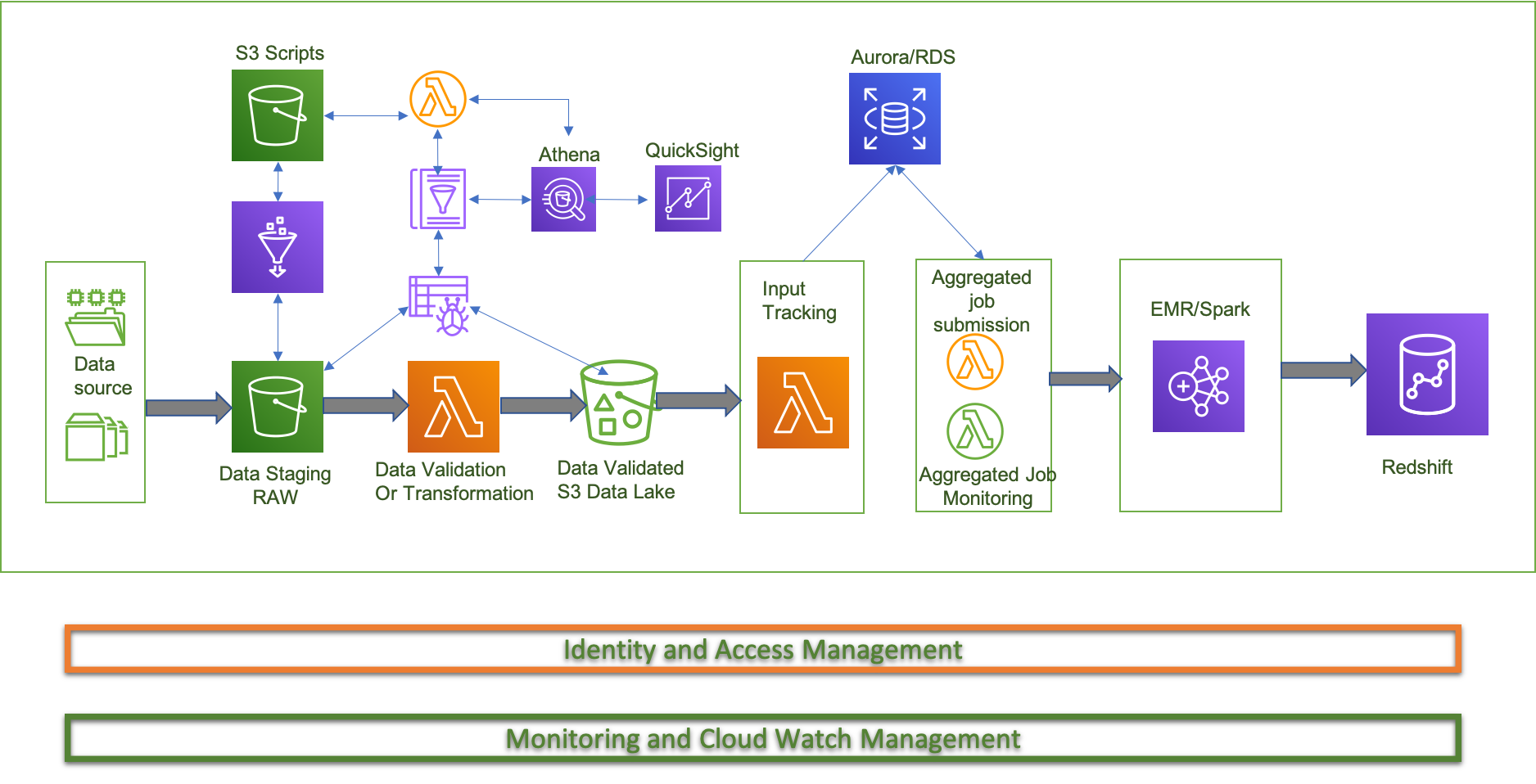
In this architecture, each location on S3 stores data at a certain state of transformation. When new data is placed at a specific location, an S3 event is raised that triggers a Lambda function responsible for the next transformation in the chain. You can use this event-driven approach to create sophisticated ETL processes, and to syndicate data availability at a given point in the chain.
Aggregation Job Submission Layer The Lambda function in this layer iterates over the list of open jobs (jobs that are not in "Running" state) in the state management store and submits a job if the respective precondition criteria configured for that job are met.
Which File formats should I chose?
As opposed to an RDBMS storage engine, an array of elements such as file sizes, type of storage (row vs. columnar), degree of compression, indexing, schemas, and block sizes. These are related to the Hadoop-oriented ecosystem of tools commonly used for accessing data in a lake.
File Size
A small file is one which is significantly smaller than the Hadoop file system (HDFS) default block size, which is 128 MB. If we are storing small files, given the large data volumes of a data lake, we will end up with a very large number of files. The takeaway here is that Hadoop ecosystem tools are not optimized for efficiently accessing small files. They are primarily designed for large files, typically an even multiple of the block size.
Apache ORC is a prominent columnar file format designed for Hadoop workloads. The ability to read, decompress, and process only the values that are required for the current query is made possible by columnar file formatting. While there are multiple columnar formats available, many large Hadoop users have adopted ORC. For instance, Facebook uses ORC to save tens of petabytes in their data warehouse. They have also demonstrated that ORC is significantly faster than RC File or Parquet. Yahoo also uses ORC to store their production data and has likewise released some of their benchmark results.
It is quite possible that one type of storage structure and file format is optimized for a particular workload but not quite suitable for another.
Apache Parquet is a file format designed to support fast data processing for complex data, with several notable characteristics:
- Columnar: Unlike row-based formats such as CSV or Avro, Apache Parquet is column-oriented – meaning the values of each table column are stored next to each other, rather than those of each record:
- Open-source: Parquet is free to use and open source under the Apache Hadoop license, and is compatible with most Hadoop data processing frameworks.
- Self-describing: In Parquet, metadata including schema and structure is embedded within each file, making it a self-describing file format.
Parquet data can be compressed using these encoding methods: 🚔
- Dictionary encoding: this is enabled automatically and dynamically for data with a small number of unique values.
- Bit packing: Storage of integers is usually done with dedicated 32 or 64 bits per integer. This allows more efficient storage of small integers.
- Run length encoding (RLE): when the same value occurs multiple times, a single value is stored once along with the number of occurrences. Parquet implements a combined version of bit packing and RLE, in which the encoding switches based on which produces the best compression results.
Performance 🚤
As opposed to row-based file formats like CSV, Parquet is optimized for performance. When running queries on your Parquet-based file-system, you can focus only on the relevant data very quickly. Moreover, the amount of data scanned will be way smaller and will result in less I/O usage. As I mentioned above, Parquet is a self-described format, so each file contains both data and metadata. Parquet files are composed of row groups, header and footer. Each row group contains data from the same columns. The same columns are stored together in each row group:
This structure is well-optimized both for fast query performance, as well as low I/O (minimizing the amount of data scanned). For example, if you have a table with 1000 columns, which you will usually only query using a small subset of columns. Using Parquet files will enable you to fetch only the required columns and their values, load those in memory and answer the query. If a row-based file format like CSV was used, the entire table would have to have been loaded in memory, resulting in increased I/O and worse performance.
Compressed CSVs has 18 columns and weighs 27 GB on S3. Athena has to scan the entire CSV file to answer the query, so we would be paying for 27 GB of data scanned. At higher scales, this would also negatively impact performance. Converting compressed CSV files to Apache Parquet, you end up with a similar amount of data in S3. However, because Parquet is columnar, Athena needs to read only the columns that are relevant for the query being run – a small subset of the data. In this case, Athena had to scan 0.22 GB of data, so instead of paying for 27 GB of data scanned we pay only for 0.22 GB.
Using Parquet is a good start; however, optimizing data lake queries doesn’t end there. You often need to clean, enrich and transform the data, perform high-cardinality joins and implement a host of best practices in order to ensure queries are consistently answered quickly and cost-effectively.
Summary
In the next part, we will discuss design security, data security and metadata cataloging.
Reference: Thanks to AWS
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Kafka here
🔗 Read more about Spark here
🔗 Read more about Data Lakes Part 1here
🔗 Read more about Data Lakes Part 3here
🔗 Read more about Data Lakes Part 4here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here