Build confidence with Kafka
Apache Kafka is a powerful open-source streaming platform that enables businesses to manage data streams effectively. However, building enterprise-grade solutions with Kafka requires a comprehensive understanding of its key components. In this article, we will explore the four core components of Kafka and their purpose in developing a robust streaming platform.
What is Kafka? Apache Kafka is an open-source stream-processing software platform developed by the Apache Software Foundation, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
Apache Kafka
Apache Kafka is an event streaming platform. It became the de facto standard for so many different use cases due to combination of four powerful concepts:
- Publish and subscribe to streams of events, similar to a message queue or enterprise messaging system
- Store streams of events in a fault-tolerant storage as long as you want (hours, days, months, forever)
- Process streams of events in real time, as they occur
- Integration of different sources and sinks (no matter if real time, batch or request-response)
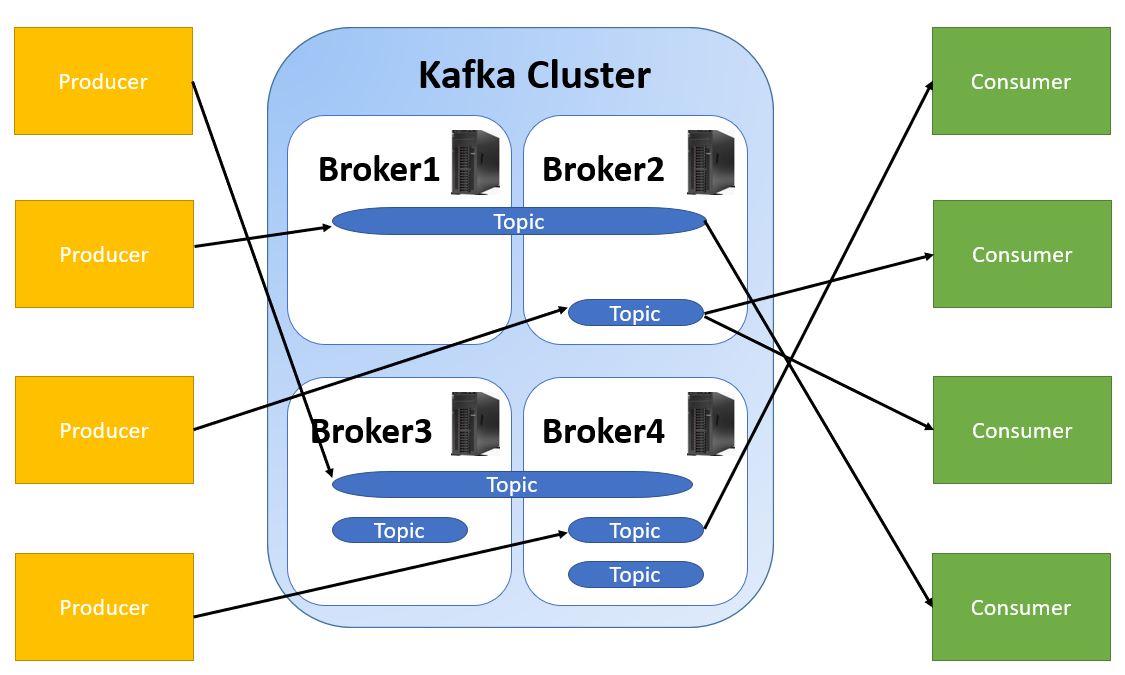
Kafka Architecture
Apache Kafka is a powerful streaming platform that can be used to build robust and scalable data processing applications. In this article, we discussed the core components of Kafka, including brokers, clients, connectors, and Kafka Streams. We also highlighted the additional components needed for enterprise-level Kafka deployment. By leveraging Kafka's rich ecosystem of tools and libraries, developers can build powerful real-time applications that meet their specific needs.
Building Enterprise-Grade Solutions with Apache Kafka
Apache Kafka is a powerful open-source streaming platform that enables businesses to manage data streams effectively. However, building enterprise-grade solutions with Kafka requires a comprehensive understanding of its key components. In this article, we will explore the four core components of Kafka and their purpose in developing a robust streaming platform.
Kafka Broker
The Kafka Broker is the core component of the Kafka platform that is responsible for receiving and storing data in the form of messages. It is a distributed system that manages data partitions and ensures that messages are delivered to the right consumers. Brokers can be scaled horizontally to handle increased message throughput, making Kafka a highly scalable platform.
Kafka Client APIs
Kafka provides a set of client APIs that allow developers to produce and consume messages from the Kafka Broker. These APIs enable developers to write custom code that integrates Kafka with their existing systems. The APIs are available in several programming languages, including Java, Python, and Scala, making it easy for developers to work with Kafka using their preferred language.
Kafka Connect
Kafka Connect is a framework for building and running connectors that move data between Kafka and external systems. It provides a set of pre-built connectors for popular data sources such as databases, file systems, and message queues. Connectors can be run as standalone processes or as part of a distributed system, allowing businesses to integrate Kafka with their existing infrastructure seamlessly.
Kafka Streams
Kafka Streams is a library for building real-time stream processing applications using Kafka. It provides a set of APIs for processing streams of data and can be used to implement a range of use cases, such as data transformation, aggregation, and filtering. Kafka Streams is highly scalable, fault-tolerant, and can be deployed in a distributed environment.
Kafka Brokers: The Core of Apache Kafka
Apache Kafka is an open-source streaming platform that provides all the necessary components for managing data streams. Kafka brokers are the primary storage and messaging components of the platform. They are responsible for storing and managing the streams of data that are produced and consumed by Kafka clients.
Kafka Broker Architecture
The servers that run the Kafka cluster are called brokers. A Kafka cluster typically consists of multiple brokers, and each broker has its own unique ID. The brokers work together to provide a fault-tolerant and scalable messaging system. They store the streams of data in topics, which are partitions of the data stream.
Kafka Broker Configuration
You will usually want to have at least three Kafka brokers in a cluster. However, if you want to maintain three replicas of your messages, we recommend having at least four brokers. This will give you some protection against one node failure and enough time to fix the problem. Kafka brokers use Zookeeper, which is a mandatory component in every Apache Kafka cluster.
Kafka Clients: The Producers and Consumers of Data
Kafka clients are used in applications that produce and consume messages. Apache Kafka provides a set of producer and consumer APIs that allow applications to send and receive continuous streams of data using Kafka brokers. These APIs are available as Java APIs. However, there are other alternatives such as C++, Python, Node.js, and Go language. All these other language APIs are based on librdkafka.
Kafka Connect: Ready-to-Use Connectors for Easy Data Movement
Kafka Connect is built on top of Kafka core components. It includes a bunch of ready-to-use off-the-shelf Kafka connectors that you can use to move data between Kafka brokers and other applications. For using Kafka connectors, you do not need to write code or make changes to your applications. Kafka connectors are purely based on configurations.
Kafka Connect Custom Connectors
The Kafka Connect framework allows you to develop your own custom Source and Sink connectors quickly. If you do not have a ready-to-use connector for your system, you can leverage the Kafka Connect framework to develop your own connectors.
Kafka Streams: Stream Processing Made Easy
Starting from Kafka 0.10 release, Kafka includes a powerful stream processing library called Kafka Streams. Kafka Streams allows Kafka developers to extend their standard applications with the capability for consuming, processing, and producing new data streams. Kafka Streams is capable of handling load-balancing and failover automatically.
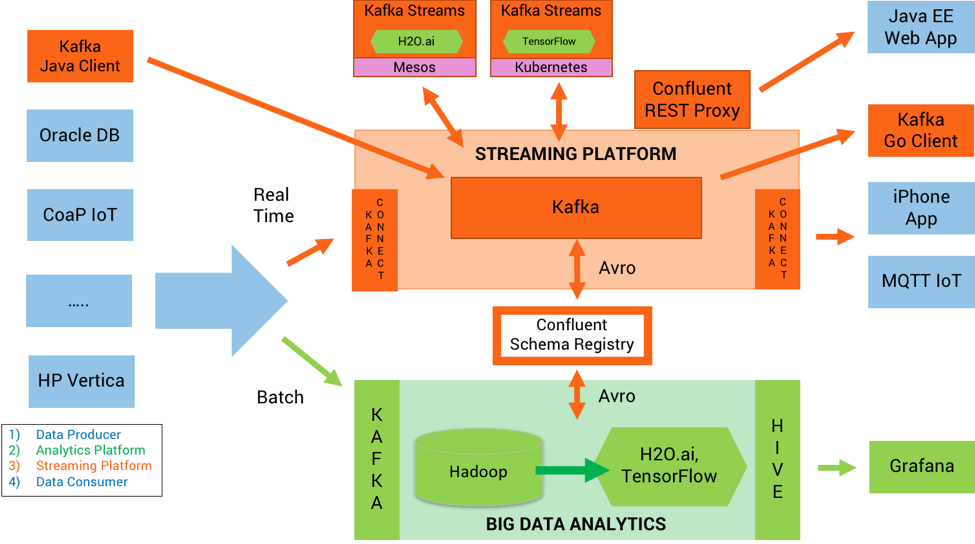
Additional Components for Enterprise-Level Kafka Deployment
The components that we discussed so far are good enough for small to medium-sized systems. However, they are not enough to handle enterprise-grade requirements. An enterprise application may need many other tools and facilities, such as:
-
Schema Management: Kafka provides Schema Registry, which is a service for storing and retrieving Avro schemas used for data serialization.
-
REST Interface: Kafka provides a REST proxy that allows you to interact with Kafka using HTTP REST calls.
-
MQTT Interface: Kafka provides an MQTT source and sink connector that allows you to ingest data from MQTT devices and publish data to MQTT brokers.
-
Auto Balancing: Kafka provides automatic partition rebalancing that ensures an even distribution of data across the cluster.
-
Operations and Control: Kafka provides tools for monitoring and managing the Kafka cluster, such as Kafka Manager, Confluent Control Center, and various command-line tools.
Additional Facts
Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another. Kafka is suitable for both offline and online message consumption. A messaging system sends messages between processes, applications, and servers. Apache Kafka is a software where topics can be defined (think of a topic as a category), applications can add, process and reprocess records. Kafka is a message bus optimized for high-ingress data streams and replay. Kafka can be seen as a durable message broker where applications can process and re-process streamed data on disk."
Kafka offers much higher performance than message brokers like RabbitMQ. It uses sequential disk I/O to boost performance, making it a suitable option for implementing queues. It can achieve high throughput (millions of messages per second) with limited resources, a necessity for big data use cases.
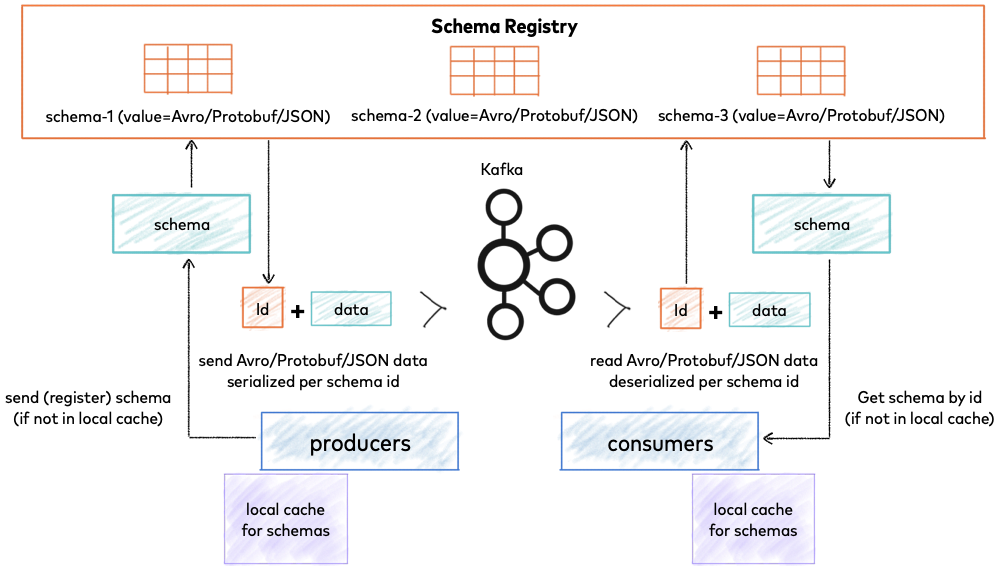
Schema management
Schema Management is an important aspect of any data pipeline that deals with structured data. In this blog, we discussed various alternatives for propagating schema over a data pipeline. Including the schema with data is not a good option as it increases the data size significantly. A better approach is to keep the schema at a central location in a schema registry that supports schema evolution and multiple versions of the evolving schema.
We also discussed the REST and MQTT interfaces for producing and consuming messages to and from Kafka brokers. RESTful HTTP protocol is useful for applications that cannot use native Kafka client APIs. In contrast, MQTT protocol is suitable for IoT devices that need to send data to Kafka brokers. We can implement an MQTT broker or use the Confluent MQTT Proxy to avoid intermediate MQTT brokers.
Auto-balancing is an essential feature of Kafka clusters that allows adding new brokers to scale up horizontally. It moves partitions from existing brokers to newly added brokers to balance the load between all brokers.
Lastly, we discussed the importance of monitoring Kafka clusters, production data pipelines, and streaming applications. We must track data streams end to end, measure system performance, and identify any problems to configure alerts to notify teams when end-to-end performance does not match SLAs.
Use Cases for Apache Kafka:
-
Messaging: Kafka works well as a replacement for a more traditional message broker. Message brokers are used for a variety of reasons (to decouple processing from data producers, to buffer unprocessed messages, etc). In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications. In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ.
-
Website Activity Tracking: Activity tracking is often very high volume as many activity messages are generated for each user page view. The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds. This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type. These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting.
-
Metrics: Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
-
Log Aggregation: Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing. Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages. This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption. In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
-
Stream Processing: Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing. For example, a processing pipeline for recommending news articles might crawl article content from RSS feeds and publish it to an "articles" topic; further processing might normalize or deduplicate this content and publish the cleansed article content to a new topic; a final processing stage might attempt to recommend this content to users. Such processing pipelines create graphs of real-time data flows based on the individual topics. Starting in 0.10.0.0, a light-weight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above. Apart from Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
-
Event Sourcing: Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka's support for very large stored log data makes it an excellent backend for an application built in this style.
-
Commit Log: Kafka can serve as a kind of external commit-log for a distributed system. The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data. The log compaction feature in Kafka helps support this usage. In this usage Kafka is similar to Apache BookKeeper project.
Topics
To begin consumption, you must first subscribe to the topics your application needs to read from.
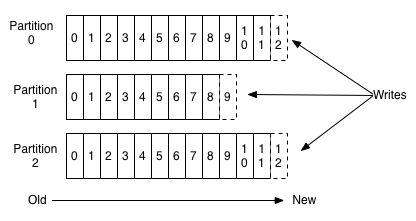
Creating a New Topic
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic my-topic
Verify the topic
kafka-topics --list --zookeeper localhost:2181
Adding Partitions
kafka-topics --zookeeper localhost:2181 --alter --topic my-topic --partitions 16
Deleting a Topic
kafka-topics --zookeeper localhost:2181 --delete --topic my-topic
Listing All Topics in a Cluster
kafka-topics --zookeeper localhost:2181 --list
Describing Topic Details
kafka-topics --zookeeper localhost:2181/kafka-cluster --describe
Show Under-replicated Partitions for topics
kafka-topics --zookeeper localhost:2181/kafka-cluster --describe --under-replicated-partitions
Producers
Produce messages standard input
kafka-console-producer --broker-list localhost:9092 --topic my-topic
Produce messages file
kafka-console-producer --broker-list localhost:9092 --topic test < messages.txt
Produce Avro messages
kafka-avro-console-producer --broker-list localhost:9092 --topic my.Topic --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}' --property schema.registry.url=http://localhost:8081
And enter a few values from the console:
{"f1": "value1"}
Consumers
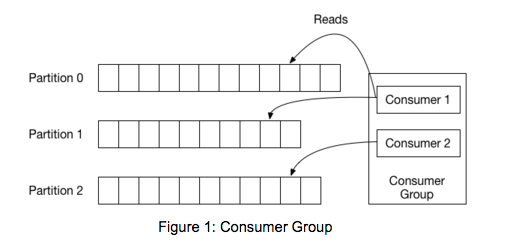
In Kafka, each topic is divided into a set of logs known as partitions. Producers write to the tail of these logs and consumers read the logs at their own pace. Kafka scales topic consumption by distributing partitions among a consumer group, which is a set of consumers sharing a common group identifier. The diagram below shows a single topic with three partitions and a consumer group with two members. Each partition in the topic is assigned to exactly one member in the group.
While the old consumer depended on Zookeeper for group management, the new consumer uses a group coordination protocol built into Kafka itself. For each group, one of the brokers is selected as the group coordinator. The coordinator is responsible for managing the state of the group. Its main job is to mediate partition assignment when new members arrive, old members depart, and when topic metadata changes. The act of reassigning partitions is known as rebalancing the group.
When a group is first initialized, the consumers typically begin reading from either the earliest or latest offset in each partition. The messages in each partition log are then read sequentially. As the consumer makes progress, it commits the offsets of messages it has successfully processed. For example, in the figure below, the consumer’s position is at offset 6 and its last committed offset is at offset 1.
Consume messages
Start a consumer from the beginning of the log
kafka-console-consumer --bootstrap-server localhost:9092 --topic my-topic --from-beginning
Consume 1 message
kafka-console-consumer --bootstrap-server localhost:9092 --topic my-topic --max-messages 1
Consume 1 message from __consumer_offsets
kafka-console-consumer --bootstrap-server localhost:9092 --topic __consumer_offsets --formatter 'kafka.coordinator.GroupMetadataManager$OffsetsMessageFormatter' --max-messages 1
Consume, specify consumer group:
kafka-console-consumer --topic my-topic --new-consumer --bootstrap-server localhost:9092 --consumer-property group.id=my-group
Consume Avro messages
kafka-avro-console-consumer --topic position-reports --new-consumer --bootstrap-server localhost:9092 --from-beginning --property schema.registry.url=localhost:8081 --max-messages 10
kafka-avro-console-consumer --topic position-reports --new-consumer --bootstrap-server localhost:9092 --from-beginning --property schema.registry.url=localhost:8081
Consumers admin operations
List Groups
kafka-consumer-groups --new-consumer --list --bootstrap-server localhost:9092
Describe Groups
kafka-consumer-groups --bootstrap-server localhost:9092 --describe --group testgroup
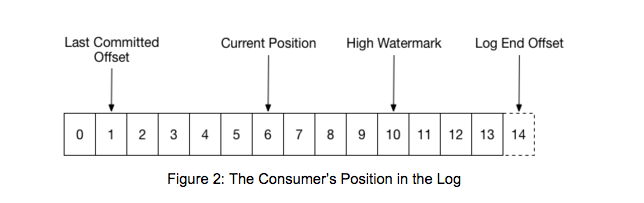
When a partition gets reassigned to another consumer in the group, the initial position is set to the last committed offset. If the consumer in the example above suddenly crashed, then the group member taking over the partition would begin consumption from offset 1. In that case, it would have to reprocess the messages up to the crashed consumer’s position of 6.
The diagram also shows two other significant positions in the log. The log end offset is the offset of the last message written to the log. The high watermark is the offset of the last message that was successfully copied to all of the log’s replicas. From the perspective of the consumer, the main thing to know is that you can only read up to the high watermark. This prevents the consumer from reading unreplicated data which could later be lost.
Config
Set the retention for the topic
kafka-configs --zookeeper localhost:2181 --alter --entity-type topics --entity-name my-topic --add-config retention.ms=3600000
Show all configuration overrides for a topic
kafka-configs --zookeeper localhost:2181 --describe --entity-type topics --entity-name my-topic
Delete a configuration override for retention.ms for a topic
kafka-configs --zookeeper localhost:2181 --alter --entity-type topics --entity-name my-topic --delete-config retention.ms
Performance
Producer
kafka-producer-perf-test --topic position-reports --throughput 10000 --record-size 300 --num-records 20000 --producer-props bootstrap.servers="localhost:9092"
ACLs
kafka-acls --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Bob --consumer --topic topicA --group groupA
kafka-acls --authorizer-properties zookeeper.connect=localhost:2181 --add --allow-principal User:Bob --producer --topic topicA
List the ACLs
kafka-acls --authorizer-properties zookeeper.connect=localhost:2181 --list --topic topicA
Zookeeper
Enter zookeepr shell:
zookeeper-shell localhost:2182 ls /
///Sample program of spark - kafka integration
package com.applecandy.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
import java.util.regex.Pattern
import java.util.regex.Matcher
import Utilities.\_
import org.apache.spark.streaming.kafka.\_
import kafka.serializer.StringDecoder
/\*_ Working example of listening for log data from Kafka's testLogs topic on port 9092. _/
object KafkaExample {
def main(args: Array[String]) {
// Create the context with a 1 second batch size
val ssc = new StreamingContext("local[*]", "KafkaExample", Seconds(1))
setupLogging()
// Construct a regular expression (regex) to extract fields from raw Apache log lines
val pattern = apacheLogPattern()
// hostname:port for Kafka brokers, not Zookeeper
val kafkaParams = Map("metadata.broker.list" -> "localhost:9092")
// List of topics you want to listen for from Kafka
val topics = List("testLogs").toSet
// Create our Kafka stream, which will contain (topic,message) pairs. We tack a
// map(_._2) at the end in order to only get the messages, which contain individual
// lines of data.
val lines = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topics).map(_._2)
// Extract the request field from each log line
val requests = lines.map(x => {val matcher:Matcher = pattern.matcher(x); if (matcher.matches()) matcher.group(5)})
// Extract the URL from the request
val urls = requests.map(x => {val arr = x.toString().split(" "); if (arr.size == 3) arr(1) else "[error]"})
// Reduce by URL over a 5-minute window sliding every second
val urlCounts = urls.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(300), Seconds(1))
// Sort and print the results
val sortedResults = urlCounts.transform(rdd => rdd.sortBy(x => x._2, false))
sortedResults.print()
// Kick it off
ssc.checkpoint("/checkpoint/")
ssc.start()
ssc.awaitTermination()
}
}
Performance Tips
- Picking the number of partitions for a topic There isn’t really a right answer, we expose this as an option because it is a tradeoff. The simple answer is that the partition count determines the maximum consumer parallelism and so you should set a partition count based on the maximum consumer parallelism you would expect to need (i.e. over-provision). Clusters with up to 10k total partitions are quite workable. Beyond that we don’t aggressively test (it should work, but we can’t guarantee it).
Here is a more complete list of tradeoffs to consider:
-
A partition is basically a directory of log files. Each partition must fit entirely on one machine. So if you have only one partition in your topic you cannot scale your write rate or retention beyond the capability of a single machine. If you have 1000 partitions you could potentially use 1000 machines.
-
Each partition is totally ordered. If you want a total order over all writes you probably want to have just one partition.
-
Each partition is not consumed by more than one consumer thread/process in each consumer group. This allows to have each process consume in a single threaded fashion to guarantee ordering to the consumer within the partition (if we split up a partition of ordered messages and handed them out to multiple consumers even though the messages were stored in order they would be processed out of order at times).
-
Many partitions can be consumed by a single process, though. So you can have 1000 partitions all consumed by a single process. Another way to say the above is that the partition count is a bound on the maximum consumer parallelism.
-
More partitions will mean more files and hence can lead to smaller writes if you don’t have enough memory to properly buffer the writes and coalesce them into larger writes
-
Each partition corresponds to several znodes in zookeeper. ZooKeeper keeps everything in memory so this can eventually get out of hand.
-
More partitions means longer leader fail-over time. Each partition can be handled quickly (milliseconds) but with thousands of partitions this can add up.
-
When we checkpoint the consumer position we store one offset per partition so the more partitions the more expensive the position checkpoint is.
-
It is possible to later expand the number of partitions BUT when we do so we do not attempt to reorganize the data in the topic. So if you are depending on key-based semantic partitioning in your processing you will have to manually copy data from the old low partition topic to a new higher partition topic if you later need to expand.
-
Note that I/O and file counts are really about #partitions/#brokers, so adding brokers will fix problems there; but ZooKeeper handles all partitions for the whole cluster so adding machines doesn’t help.
-
Tuning virtual memory
- Linux virtual memory automatically adjusts to accommodate the workload of a system. Because Kafka relies heavily on the system page cache, when a virtual memory system swaps to disk it is possible that insufficient memory is allocated to the page cache. Generally speaking, swapping has a noticeable negative impact on all aspects of Kafka performance, and should be avoided.
- If you do not configure swap space, then you can avoid altogether swapping-related performance issues. However, swap provides an important safety mechanism in case of a catastrophic system issue. For example, swap prevents the OS from abruptly killing a process when faced with an out-of-memory condition.
- To avoid swap performance issues and simultaneously have the assurance of a safety net, set the vm.swappiness parameter to a very low value, such as 1. The vm.swappiness value is a percentage of how likely the virtual memory subsystem is to use swap space rather than drop pages from the page cache. The higher the value of the parameter, the more aggressively the kernel will swap. Reducing the page cache size is preferable to adjusting swap. However, it is not recommended to use a value of 0, because it would never allow a swap under any circumstances, thus forfeiting the safety net afforded when using this parameter.
-
Lagging replicas
- ISR is the set of replicas that are fully sync-ed up with the leader. In other words, every replica in the ISR has written all committed messages to its local log. In steady state, ISR should always include all replicas of the partition. Occasionally, some replicas fall out of the insync replica list. This could either be due to failed replicas or slow replicas.
- A replica can be dropped out of the ISR if it diverges from the leader beyond a certain threshold. This is controlled by the following parameter: replica.lag.time.max.ms
- This is typically set to a value that reliably detects the failure of a broker. You can set this value appropriately by observing the value of the replica’s minimum fetch rate that measures the rate of fetching messages from the leader (kafka.server:type=ReplicaFetcherManager,name=MinFetchRate,clientId=Replica). If that rate is n, set the value for this parameter to larger than 1/n * 1000.
-
Increasing consumer throughput
- First, try to figure out if the consumer is just slow or has stopped. To do so, you can monitor the maximum lag metric kafka.consumer:type=ConsumerFetcherManager,name=MaxLag,clientId=([-.\w]+) that indicates the number of messages the consumer lags behind the producer. Another metric to monitor is the minimum fetch rate kafka.consumer:type=ConsumerFetcherManager,name=MinFetchRate,clientId=([-.\w]+) of the consumer. If the MinFetchRate of the consumer drops to almost 0, the consumer is likely to have stopped. If the MinFetchRate is non-zero and relatively constant, but the consumer lag is increasing, it indicates that the consumer is slower than the producer. If so, the typical solution is to increase the degree of parallelism in the consumer. This may require increasing the number of partitions of a topic.
-
Handling large message sizes
-
We strongly recommend that you adhere to the default maximum size of 1 MB for messages. When it is absolutely necessary to increase the maximum message size, the following are a few of the many implications you should consider. Also consider alternative options such as using compression and/or splitting up messages.
-
Heap fragmentation
-
Consistently large messages likely cause heap fragmentation on the broker side, requiring significant JVM tuning to maintain consistent performance. Dirty page cache
-
Accessing messages that are no longer available in the page cache is slow. With larger messages, fewer messages can fit in the page cache, causing degraded performance.
-
Kafka client buffer sizes
-
Default buffer sizes on the client side are tuned for small messages (<1MB). You will have to tune client side buffers on both the producer and consumer to properly handle the messages. See the discussion about max.message.bytes.
-
To configure Kafka to handle larger messages, set the following configuration parameters at the level you need, in Producer, Consumer and Topic. If all topics needs this configuration, set it in the Broker configuration, but this is not recommended for the reasons listed above.
-
Will Kafka replace a database?
The answer to this question is "it depends". Often, Kafka and databases are complementary as each database has specific features, guarantees and query options. Apache Kafka is a database and it provides ACID guarantees. Kafka is used by hundreds of companies for mission-critical deployments. Kafka is an event streaming platform for messaging, storage, processing and integration at scale in real time with zero downtime and zero data loss.
Kafka has characteristics of a database engine:
- Kafka can store data forever(configurable) in a durable and high available manner providing ACID guarantees
- Query historical data
- KsqlDB or Tiered Storage for data processing and event-based long-term storage
- Stateful applications can be built leveraging Kafka clients (microservices, business applications) elimating the need for another external database
- Not a replacement for existing databases like MySQL, MongoDB, Elasticsearch or Hadoop. Purpose-built materialized views are created and updated in real time from the central event-based infrastructure
- Other options for bi-directional pull and push based integration between Kafka and databases are available
Kafka Streams and ksqlDB(the event streaming database for Kafka) allow to build stateful streaming applications; including powerful concepts like joins, sliding windows and interactive queries of the state. Kafka Streams and ksqlDB leverage RocksDB. RocksDB is a key-value store for running mission-critical workloads. It is optimized for fast, low latency storage. In Kafka Streams applications, that solves the problem of abstracting access to local stable storage instead of using an external database.
The client application keeps the data in its own application for real time joins and other data correlations. It combines the concepts of a STREAM (unchangeable event) and a TABLE (updated information like in a relation database). Instead, it is a distributed cluster of client instances to provide high availablity and parallelizing data processing. Even if something goes down (VM, container, disk, network), the overall system will not lose and data and continue running 24/7.
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Spark here
🔗 Read more about Data Lakes here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here