Build confidence with Cassandra
Apache Cassandra is a distributed, NoSQL Database management system (DBMS) designed for high volumes of data. Learn more about the Architecture and the derisk approach when working with Cassandra.

What is Cassandra? The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
What is Cassandra?
Cassandra offers users “blazingly fast writes,” and the speed or accuracy is unaffected by large volumes of data.
-
Massively scalable architecture – a master-less design where all nodes are the same.
-
Linear scale performance – online node additions produce predictable increases in performance.
-
Transparent fault detection and recovery –easy failed node recovery.
-
Flexible, dynamic schema data modeling –easily supports structured, semi-structured, and unstructured data.
-
Guaranteed data safety – commit log design ensures no data loss.
-
Active everywhere design – all nodes may be written to and read from.
-
Tunable data consistency – support for strong or eventual data consistency.
-
Multi-data center replication – cross data center and multi-cloud availability zone support for writes/reads built in.
-
Data compression – data compressed up to 80% without performance overhead.
-
CQL (Cassandra Query Language) – a SQL – like language that makes moving from an RDBMS very easy.
-
Designed on principles of Google’s Big Table and Dynamo Paper by Amazon
Some more notes on Bigtable
Architecture
The architecture consists of a cluster of nodes, any and all of which can accept a read or write request. This is a key aspect of its architecture, as there are no master nodes. Instead, all nodes communicate equally.
While nodes are the specific location where data lives on a cluster, the cluster is the complete set of data centers where all data is stored for processing. Related nodes are grouped together in data centers. This type of structure is built for scalability and when additional space is needed, nodes can simply be added. The result is that the system is easy to expand, built for volume, and made to handle concurrent users across an entire system.
Its structure also allows for data protection. To help ensure data integrity, Cassandra has a commit log. This is a backup method and all data is written to the commit log to ensure data is not lost. The data is then indexed and written to a memtable. The memtable is simply a data structure in the memory where Cassandra writes. There is one active memtable per table.
When memtables reach their threshold, they are flushed on a disk and become immutable SSTables. More simply, this means that when the commit log is full, it triggers a flush where the contents of memtables are written to SSTables. The commit log is an important aspect of Cassandra’s architecture because it offers a failsafe method to protect data and to provide data integrity.
VNodes - Each node is assigned a non-contiguous token ranges for better load balancing/distribution across the cluster. Multiple token ranges across each node allows multiple nodes to participate in bootstrapping and streaming data to new nodes. Automatic token range recalculation prevents existing nodes from needing to be reconfigured. New token allocation algorithm using vnodes and murmur3partition.
Data organization - From Cassandra 3.0, the storage engine was rewritten. The JSON output using sstabledump tool on mc-1-big-Data.db shows hierarchial data layout - partitions, rows and cells. Rows are now first class citizens as compared to older versions where cells were part of partitions.
Gossiper: is a peer- to peer communication protocol for node to node comunication. It holds state, data load, host id, and schema versions.
Snitch: is for directing read and write operations to appropiate nodes (data-center and rack-aware)
Flexible Data Storage – Cassandra can handle structured, semi-structured, and unstructured data, giving users flexibility with data storage.
Flexible Data Distribution – Cassandra uses multiple data centers, which allows for easy data distribution wherever or whenever needed.
Supports ACID – The properties of ACID (atomicity, consistency, isolation, and durability) are supported by Cassandra.
Data Modeling in Cassandra
Data Modeling highlights the best practices on how to model tables in Cassandra.
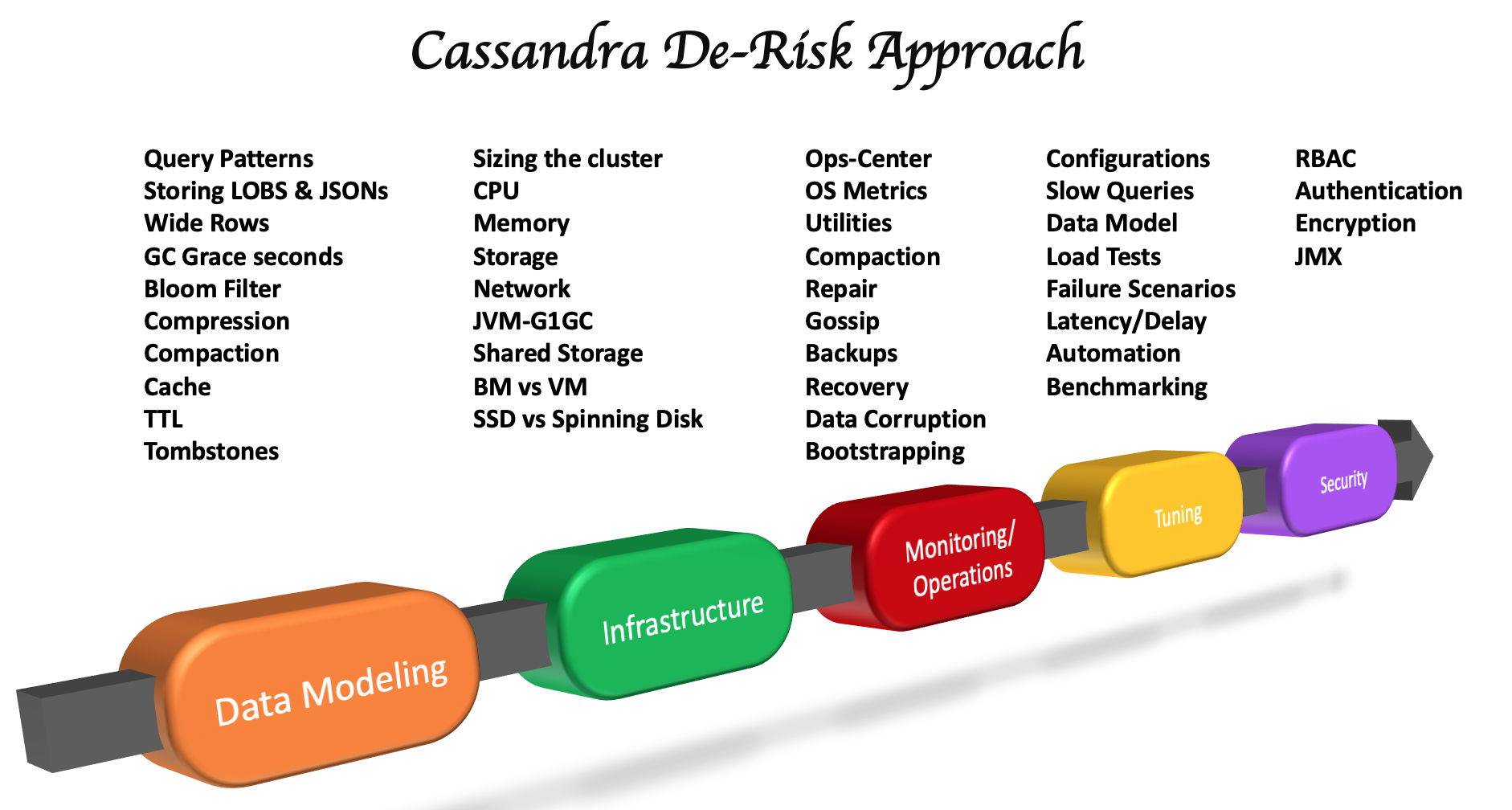
De-risk your implementation
What's new? k8aasndra
Favorite features in 
-
Zero Copy Streaming
-
Cassandra 4.0 has added support for streaming entire SSTables when possible for faster Streaming using ZeroCopy APIs. Pre-4.0, during streaming Cassandra reifies the SSTables into objects that creates unnecessary garbage and slows down the whole streaming process as some SSTables can be transferred as a whole file rather than individual partitions.
-
If enabled, Cassandra will use ZeroCopy for eligible SSTables significantly speeding up transfers and increasing throughput. A zero-copy path avoids bringing data into user-space on both sending and receiving side. Any streaming related operations will notice corresponding improvement.
-
Sender nodes send full copies of sstables along with metadata to respective receiver nodes. Receiver nodes no longer need to serialize data and rebuild metadata. Splits sstables to accommodate more usecases (DSE 6.8 only). Supports encrypted and unencrypted data.
-
Benefits of Zero Copy Streaming
-
When enabled, it permits Cassandra to zero-copy stream entire eligible SSTables between nodes, including every component. This speeds up the network transfer significantly subject to throttling specified by stream_throughput_outbound_megabits_per_sec.
-
Enabling this will reduce the GC pressure on sending and receiving node. While this feature tries to keep the disks balanced, it cannot guarantee it. This feature will be automatically disabled if internode encryption is enabled. Currently this can be used with Leveled Compaction.
-
-
Read more on Zero Copy Streaming
-
Incremental NodeSync
- When incremental NodeSync is enabled on tables, new validations will not re-validate previously validated data, drastically lowering the NodeSync workload and its impact on cluster performance.
Multi DC/Multi Region Cassandra Replication
Apache Cassandra is a proven fault-tolerant and scalable decentralized NoSQL database for today’s applications. You can deploy Cassandra on Docker containers or manage Cassandra through Kubernetes.
- Example : Cassandra cluster spans multiple data centers (all geographically miles apart) with Kubernetes. The data centers could be in different countries or regions.
Scenarios:
-
Performing live backups, where data written in one data center is asynchronously copied over to the other data center. Users in one location (for example, the United States) connect to the data center in or near that location, and users in another location (for example, India) connect to the data center in or near their location to ensure faster performance. If one data center is down, you can still serve Cassandra data from the other data center. If a few nodes in one data center are down, Cassandra data is still available without interruption.
/// Cassandra and Spark Integration
package com.applecandy.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel
import java.util.regex.Pattern
import java.util.regex.Matcher
import Utilities._
import com.datastax.spark.connector._
/** Listens to Apache log data on port 9999 and saves URL, status, and user agent
* by IP address in a Cassandra database.
*/
object CassandraExample {
def main(args: Array[String]) {
// Set up the Cassandra host address
val conf = new SparkConf()
conf.set("spark.cassandra.connection.host", "127.0.0.1")
conf.setMaster("local[*]")
conf.setAppName("CassandraExample")
// Create the context with a 10 second batch size
val ssc = new StreamingContext(conf, Seconds(10))
setupLogging()
// Construct a regular expression (regex) to extract fields from raw Apache log lines
val pattern = apacheLogPattern()
// Create a socket stream to read log data published via netcat on port 9999 locally
val lines = ssc.socketTextStream("127.0.0.1", 9999, StorageLevel.MEMORY_AND_DISK_SER)
// Extract the (IP, URL, status, useragent) tuples that match our schema in Cassandra
val requests = lines.map(x => {
val matcher:Matcher = pattern.matcher(x)
if (matcher.matches()) {
val ip = matcher.group(1)
val request = matcher.group(5)
val requestFields = request.toString().split(" ")
val url = scala.util.Try(requestFields(1)) getOrElse "[error]"
(ip, url, matcher.group(6).toInt, matcher.group(9))
} else {
("error", "error", 0, "error")
}
})
// Now store it in Cassandra
requests.foreachRDD((rdd, time) => {
rdd.cache()
println("Writing " + rdd.count() + " rows to Cassandra")
rdd.saveToCassandra("applecandy", "LogTest", SomeColumns("IP", "URL", "Status", "UserAgent"))
})
// Kick it off
ssc.checkpoint("/checkpoint/")
ssc.start()
ssc.awaitTermination()
}
}
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Kafka here
🔗 Read more about Spark here
🔗 Read more about Data Lakes here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here