Anatomy of an Analyzer
Understanding the science behind text analysis requires special algorithms that determine how a string field in a document is transformed into terms in an inverted index. This blog talks about analyzers which are a combinations of tokenizers, token filters, and character filters.

TLDR Understanding the science behind text analysis requires special algorithms that determine how a string field in a document is transformed into terms in an inverted index. This blog talks about analyzers which are a combinations of tokenizers, token filters, and character filters.
When to configure Text Analysis?
Text analysis is the process of converting unstructured text, like the body of an email or a product description, into a structured format that’s optimized for search. Analyzers are the special algorithms that determine how a string field in a document is transformed into terms in an inverted index.
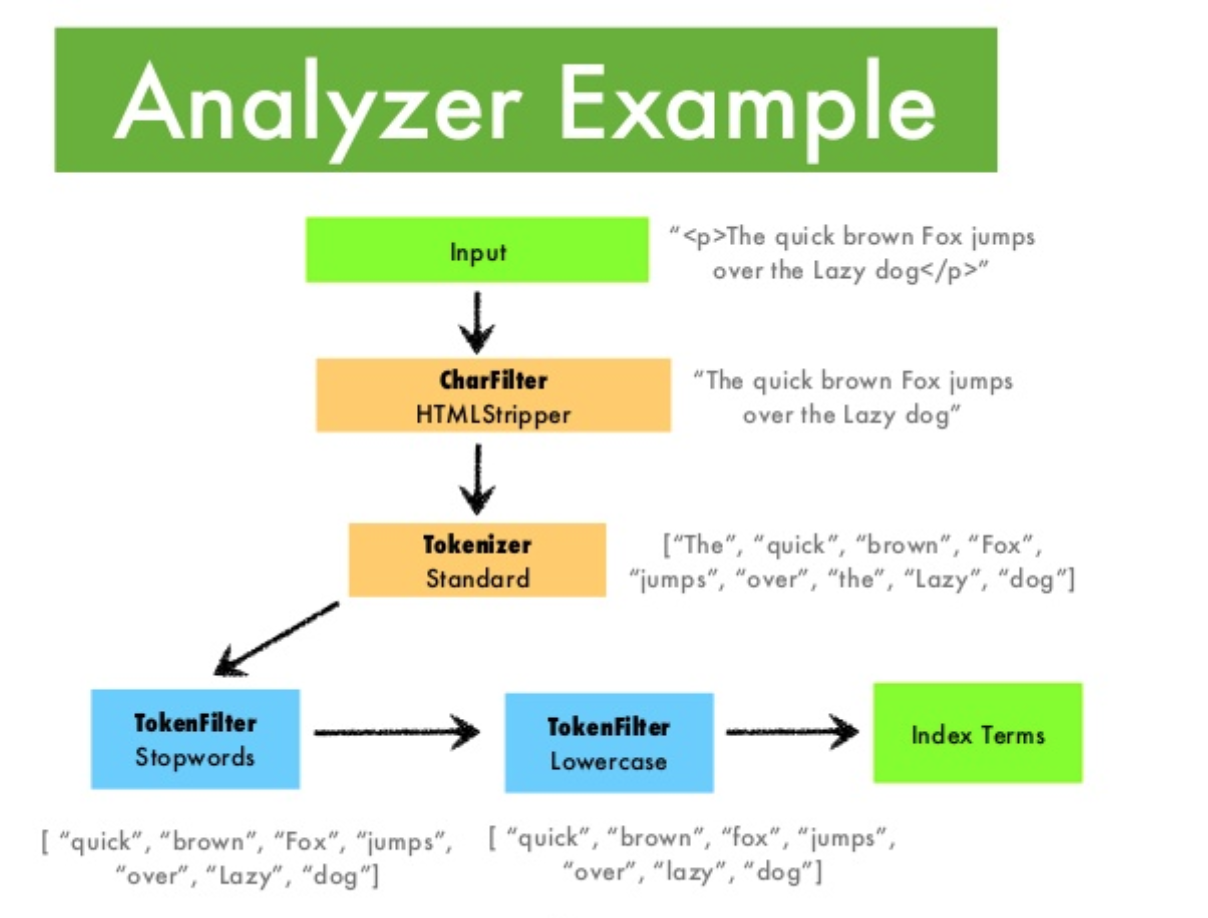
Elasticsearch performs text analysis when indexing or searching text fields. If you use text fields or your text searches aren’t returning results as expected, configuring text analysis can often help. Elasticsearch supports following use cases:
- Build a search engine
- Mine unstructured data
- Fine-tune search for a specific language
- Perform lexicographic or linguistic research
Let's understand how an analyzer works
- Analyzer is built-in or custom and it is just a package that contains three lower-level building blocks:
- Character filters
Character filters are used to preprocess the stream of characters before it is passed to the tokenizer. An example is HTML stripc character filter that strips HTML elements from a text and replaces HTML entities with their decoded value (e.g, replaces
&with &). - Tokenizers
A tokenizer receives a stream of characters, breaks it up into individual tokens (usually individual words), and outputs a stream of tokens.
- Token filters
Token filters accept a stream of tokens from a tokenizer and can modify tokens (eg lowercasing), delete tokens (eg remove stopwords) or add tokens (eg synonyms). An example is a lowercase token filter that simply changes token text to lowercase. ASCII folding token filter converts alphabetic, numeric, and symbolic characters that are not in the Basic Latin Unicode block (first 127 ASCII characters) to their ASCII equivalent, if one exists. For example, the filter changes à to a.
Characteristics of an analyzer
- An analyzer may have zero or more character filters, which are applied in order.
- An analyzer must have exactly one tokenizer.
- An analyzer may have zero or more token filters, which are applied in order.
- Tokenizer generates tokens, which will be passed on to the token filter and then eventually become terms in the inverted index.
- Certain tokenizers like ngram, edgengram can generate lots of tokens, which can cause higher disk usage.
- Tombstones are cleared out when the lucene segments merge. Searching has the priority vs indexing.
Analyzer definition for ngram analyzer has to be put in the index settings
{
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer",
"filter": ["lowercase"]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3,
"token_chars": ["letter", "digit"]
}
}
}
}
}
Let's create an index to test this:
PUT kibana_sample_data_ecommerce_reindex
{
"settings": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-1",
"number_of_replicas": "0"
},
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer",
"filter" : ["lowercase"]
},
"url_uax_analyzer": {
"tokenizer": "url_uax_tokenizer"
},
"edge_ngram_analyzer": {
"tokenizer": "edge_ngram_tokenizer",
"filter" : ["lowercase"]
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
},
"url_uax_tokenizer": {
"type": "uax_url_email",
"max_token_length": 100
},
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10,
"token_chars": [
"letter",
"digit"
]
}
}
},
"mapping ": {...}
}
"mappings": {
"properties": {
"category": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"customer_full_name": {
"type": "text",
"analyzer": "edge_ngram_analyzer",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"email": {
"type": "text",
"analyzer": "url_uax_analyzer"
},
"manufacturer": {
"type": "text",
"analyzer": "ngram_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
Lets's test the analyzer: ngram_analyzer
GET kibana_sample_data_ecommerce_reindex/_analyze
{
"text": ["TestIng TexT"],
"analyzer": "ngram_analyzer"
}
Output:
{
"tokens": [
{
"token": "tes",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 0
},
{
"token": "est",
"start_offset": 1,
"end_offset": 4,
"type": "word",
"position": 1
},
{
"token": "sti",
"start_offset": 2,
"end_offset": 5,
"type": "word",
"position": 2
},
{
"token": "tin",
"start_offset": 3,
"end_offset": 6,
"type": "word",
"position": 3
},
{
"token": "ing",
"start_offset": 4,
"end_offset": 7,
"type": "word",
"position": 4
},
{
"token": "tex",
"start_offset": 8,
"end_offset": 11,
"type": "word",
"position": 5
},
{
"token": "ext",
"start_offset": 9,
"end_offset": 12,
"type": "word",
"position": 6
}
]
}
**Let's test the next Edge ngram use case **
GET kibana_sample_data_ecommerce_reindex/_analyze
{
"text": ["TestIng TexT"],
"analyzer": "edge_ngram_analyzer"
}
Output
{
"tokens": [
{
"token": "te",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "tes",
"start_offset": 0,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "test",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 2
},
{
"token": "testi",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 3
},
{
"token": "testin",
"start_offset": 0,
"end_offset": 6,
"type": "word",
"position": 4
},
{
"token": "testing",
"start_offset": 0,
"end_offset": 7,
"type": "word",
"position": 5
},
{
"token": "te",
"start_offset": 8,
"end_offset": 10,
"type": "word",
"position": 6
},
{
"token": "tex",
"start_offset": 8,
"end_offset": 11,
"type": "word",
"position": 7
},
{
"token": "text",
"start_offset": 8,
"end_offset": 12,
"type": "word",
"position": 8
}
]
}
Full text analysis example:
The following text contains HTML snippets containing text with newline char, punctuation marks, text in upper case and non ASCII french characters. To properly analyze this, we create analyzer with html_strip char filter, standard tokenizer and token filter with work in following order - "lowercase","asciifolding","stop","apostrophe"
"This is a sample
text with some stop works, CAPS, apostrophe's their's and some french - Avec les prévisions météo, on peut savoir quel temps il fera le soir, le lendemainou dans la semaine. Quand il y a un grand soleil sur la carte,il fera chaud sur la région."
There are two analyzers
- full_text_analyzer
- full_text_analyzer_reverse (The reverse analyzer is useful for searching text in the middle)
PUT full_text_analyzer_test
{
"settings": {
"number_of_replicas": 0,
"number_of_shards": 1,
"analysis": {
"analyzer": {
"full_text_analyzer" :{
"char_filter": [ "html_strip" ],
"tokenizer" : "standard",
"filter" : ["lowercase","asciifolding","stop","apostrophe"]
},
"full_text_analyzer_reversed" :{
"char_filter": [ "html_strip" ],
"tokenizer" : "standard",
"filter" : ["lowercase","asciifolding","stop","apostrophe","reverse"]
}
}
}
},
"mappings": {
"properties": {
"text" :{
"type": "text",
"analyzer": "standard",
"fields": {
"analyzed" : {
"type" : "text",
"analyzer" : "full_text_analyzer"
},
"analyzed_reversed" : {
"type" : "text",
"analyzer" : "full_text_analyzer_reversed"
}
}
}
}
}
}
POST full_text_analyzer_test/_doc/1
{
"text" : """<html>This is a sample <br/>
text with some stop works, CAPS, apostrophe's their's and some french - Avec les prévisions météo, on peut savoir quel temps il fera le soir, le lendemainou dans la semaine. Quand il y a un grand soleil sur la carte,il fera chaud sur la région.</html>"""
}
To search from the middle of the text use full_text_analyzer_reversed analyzer. Here is the example of searching for the word ‘sample’ using the word from the middle ‘ample’. To do the search, first reverse the query string ‘ample’ to ‘elpma’ and then search against text.analyzed_reversed field:
GET full_text_analyzer_test/_search
{
"query": {
"prefix": {
"text.analyzed_reversed": {
"value": "elpma"
}
}
}
}
Output
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "full_text_analyzer_test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"text" : """<html>This is a sample <br/>
text with some stop works, CAPS, apostrophe's their's and some french - Avec les prévisions météo, on peut savoir quel temps il fera le soir, le lendemainou dans la semaine. Quand il y a un grand soleil sur la carte,il fera chaud sur la région.</html>"""
}
}
]
}
}
Normalizer
Normalizer is used for analyzing input for the keyword field. Unlike analyzer, normalizer will always emit only one token. In the following example, the “city_name” field is a keyword field, city_name.normalized is also a keyword field but uses my_normalizer. My_normalizer lowercases and converts the input to ASCII.
PUT normlizer_text
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"type": "custom",
"char_filter": [],
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"properties": {
"city_name": {
"type": "keyword",
"fields": {
"normalized" :{
"type" : "keyword",
"normalizer" : "my_normalizer"
}
}
}
}
}
}
Index two documents:
PUT normlizer_text/_doc/1
{
"city_name" : "New DELHI"
}
PUT normlizer_text/_doc/2
{
"city_name" : "San FranciscO"
}
Query examples:
Aggregation on keyword fields -with and without normalizer. This shows how documents are normalized:
GET normlizer_text/_search
{
"size": 0,
"aggs": {
"city": {
"terms": {
"field": "city_name",
"size": 10
}
},
"city_normalized": {
"terms": {
"field": "city_name.normalized",
"size": 10
}
}
}
}
Output
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"city": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "New DELHI",
"doc_count": 1
},
{
"key": "San FranciscO",
"doc_count": 1
}
]
},
"city_normalized": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "new delhi",
"doc_count": 1
},
{
"key": "san francisco",
"doc_count": 1
}
]
}
}
}
Searching:
GET normlizer_text/_search
{
"query": {
"term": {
"city_name": "new delhi"
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
GET normlizer_text/_search
{
"query": {
"term": {
"city_name.normalized": "new delhi"
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "normlizer_text",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"city_name" : "New DELHI"
}
}
]
}
}
Further Reading
🔗 Read more about Snowflake here
🔗 Read more about Cassandra here
🔗 Read more about Elasticsearch here
🔗 Read more about Kafka here
🔗 Read more about Spark here
🔗 Read more about Data Lakes here
🔗 Read more about Redshift vs Snowflake here
🔗 Read more about Best Practices on Database Design here