Nidhi Vichare
Author of The Meaning LayerVP, Data, AI & Platform Architecture · Author of The Meaning Layer
I lead enterprise AI from strategy to production, and I measure it with causal frameworks, not dashboard correlations. I build the organizations, architectures, and operating models behind platforms protecting renewal revenue on a multi-billion-dollar enterprise book and powering a $1B+ advertising revenue line. I wrote The Meaning Layer to make the case for governing the meaning AI actually runs on.


The Meaning Layer
Govern meaning before your AI decides for you.
The new IP isn't your data, it's what your data means. Govern it, or your agents will guess. A chapter-by-chapter guide to governing the meaning your AI runs on.
I built the platforms behind
billion-dollar revenue lines
From Samsung's billion-dollar ad attribution engine to the platform protecting Cisco's multi-billion-dollar renewal book.
I architect where data becomes measurable business value.
Twenty years leading enterprise data & AI: setting the strategy, securing executive and board buy-in, and building the organizations that deliver it. From first pipeline to billion-dollar attribution.
Unlocking data and AI,
one essay at a time.
A running collection of essays on applied enterprise AI. The architecture, measurement, and leadership calls that determine which AI programs actually work. Written for senior data and AI leaders making the decisions that do not make the slides.
Catalog strategy. Causal measurement. Agent architectures. And the craft of senior leadership in a year where every slide has AI on it.
46 essays · Enterprise AI strategy, data architecture, and leadership.
Nidhi Vichare is an enterprise AI and data executive, platform architect, and author of The Meaning Layer. She writes about enterprise AI strategy, data architecture, causal measurement, AI ROI, agentic systems, and modern leadership for senior data and AI leaders.
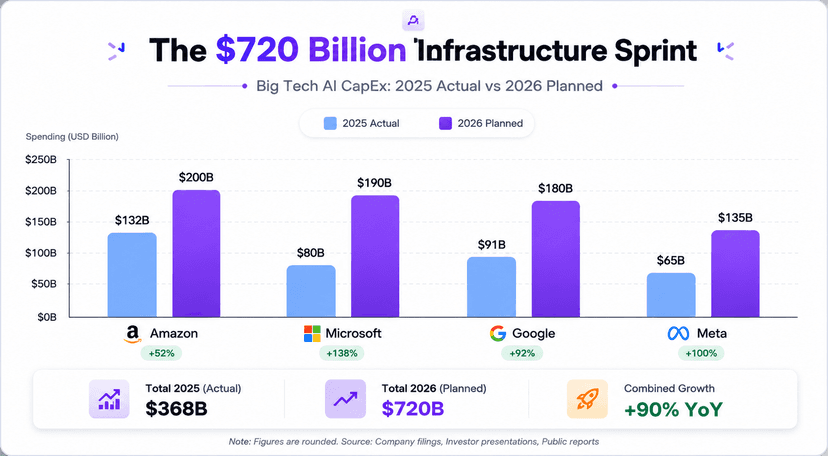





Enterprise-scale systems I've designed and shipped.