Chatting Over Documents with OpenAI, LangChain and Pinecone
Explore the creation of an advanced document-based question-answering system using LangChain and Pinecone. By capitalizing on the latest advancements in large language models (LLMs) like OpenAI GPT-4, we'll construct a document question-answer system with the LangChain and Pinecone.

Introduction
In this blog post, we will explore the significant advantages of utilizing semantic search in conjunction with GPT QnA, as opposed to relying solely on fine-tuned GPT models. By harnessing the combined power of semantic search and GPT QnA, we can achieve superior question-answering capabilities that are more accurate, contextually aware, and adaptable. Further we will explore the creation of an advanced document-based question-answering system using LangChain and Pinecone. By capitalizing on the latest advancements in large language models (LLMs) like OpenAI GPT-4 and ChatGPT, we'll construct a cutting-edge Document question-answer system that pushes the boundaries of AI technology.
Background
LangChain and Pinecone are two powerful tools that enable the development of applications driven by language models and provide efficient vector search capabilities, respectively. With LangChain's framework and Pinecone's vector database, we can harness the full potential of LLMs to build a highly accurate and context-aware QnA system.
Objective
The objective of this blog post is to guide developers and AI enthusiasts in constructing an advanced Document QnA system. We will delve into the integration of LangChain and Pinecone, demonstrating how to leverage these tools to generate precise answers based on specific documents. We will get into the terminology and build core concepts before we start understanding how to build the QnA system with OPL(OpenAI, Pinecone and LangChain)
Terms
- Pinecone
- Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. It combines state-of-the-art vector search libraries, advanced features such as filtering, and distributed infrastructure to provide high performance and reliability at any scale. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
- GPT
- Generative Pre-trained Transformer 3 (GPT-3) is a large language model released by OpenAI in 2020. Like its predecessor GPT-2, it is a decoder-only transformer model of deep neural network, which uses attention in place of previous recurrence- and convolution-based architectures
- LangChain
-
LangChain is a framework designed to simplify the creation of applications using large language models (LLMs). As a language model integration framework, LangChain's use-cases largely overlap with those of language models in general, including document analysis and summarization, chatbots, and code analysis.
Langchain Models, Indexes and Chains
- Models: LangChain supports various model types and model integrations, allowing users to leverage different language models for their tasks. - Indexes: LangChain facilitates the combination of language models with user-provided text data, offering guidance on best practices for incorporating such data effectively. - Chains: LangChain goes beyond a single call to a Language Model (LLM) and enables sequences of calls, either to an LLM or other utilities. It provides a standardized interface for creating chains, integrates with multiple tools, and offers end-to-end chains for common applications. - Vectorization
- Vectorization is the general process of converting text into numerical vector representations, while embedding specifically refers to learning vector representations through deep learning, often using an embedding layer. Vectorization encompasses various techniques, including traditional methods like bag-of-words or TF-IDF, while embedding involves learning dense, lower-dimensional vector representations that capture the semantic meaning or contextual information of the text.
- Semantic Search
- Semantic search is an advanced search technique that aims to improve the accuracy and relevance of search results by understanding the meaning and intent behind user queries and the content being searched. Unlike traditional keyword-based search, which matches search terms directly, semantic search considers the context, intent, and relationships between words and concepts. Semantic search utilizes natural language processing (NLP) techniques, machine learning algorithms, and knowledge graphs to extract semantic meaning from search queries and documents.
What are the advantages of using Sematic Search with GPT?
- Broader Knowledge Coverage
- Semantic Search + GPT QnA identifies relevant passages from a wide range of documents, ensuring comprehensive and up-to-date answers
- Fine-tuned GPT models rely solely on training knowledge, which can be outdated or lack coverage of new information.
- Contextually Precise Answers
- Semantic Search + GPT QnA generates highly tailored answers by grounding responses in specific passages, resulting in greater precision.
- Fine-tuned GPT models may generate less precise or unrelated answers based on general knowledge.
- Adaptability and Flexibility
- Semantic Search + GPT QnA can easily update information sources or be fine-tuned for specific domains without retraining the entire GPT model.
- Fine-tuning GPT models requires time-consuming and computationally expensive retraining.
- Enhanced Handling of Ambiguous Queries
- Semantic Search helps disambiguate queries by identifying relevant passages, enabling more accurate answers.
- Fine-tuned GPT models may struggle with ambiguous queries without proper context, leading to less accurate or irrelevant answers.
What is the reference Architecture for LLM Stack - OpenAI/GPT, LangChain and Pinecone?
In this post, we explore a reference architecture for the Language Model (LLM) app stack, with a special focus on the utilization of Pinecone and Langchain. We will outline the steps required to create vector embeddings, which enable efficient storage and retrieval of textual data.
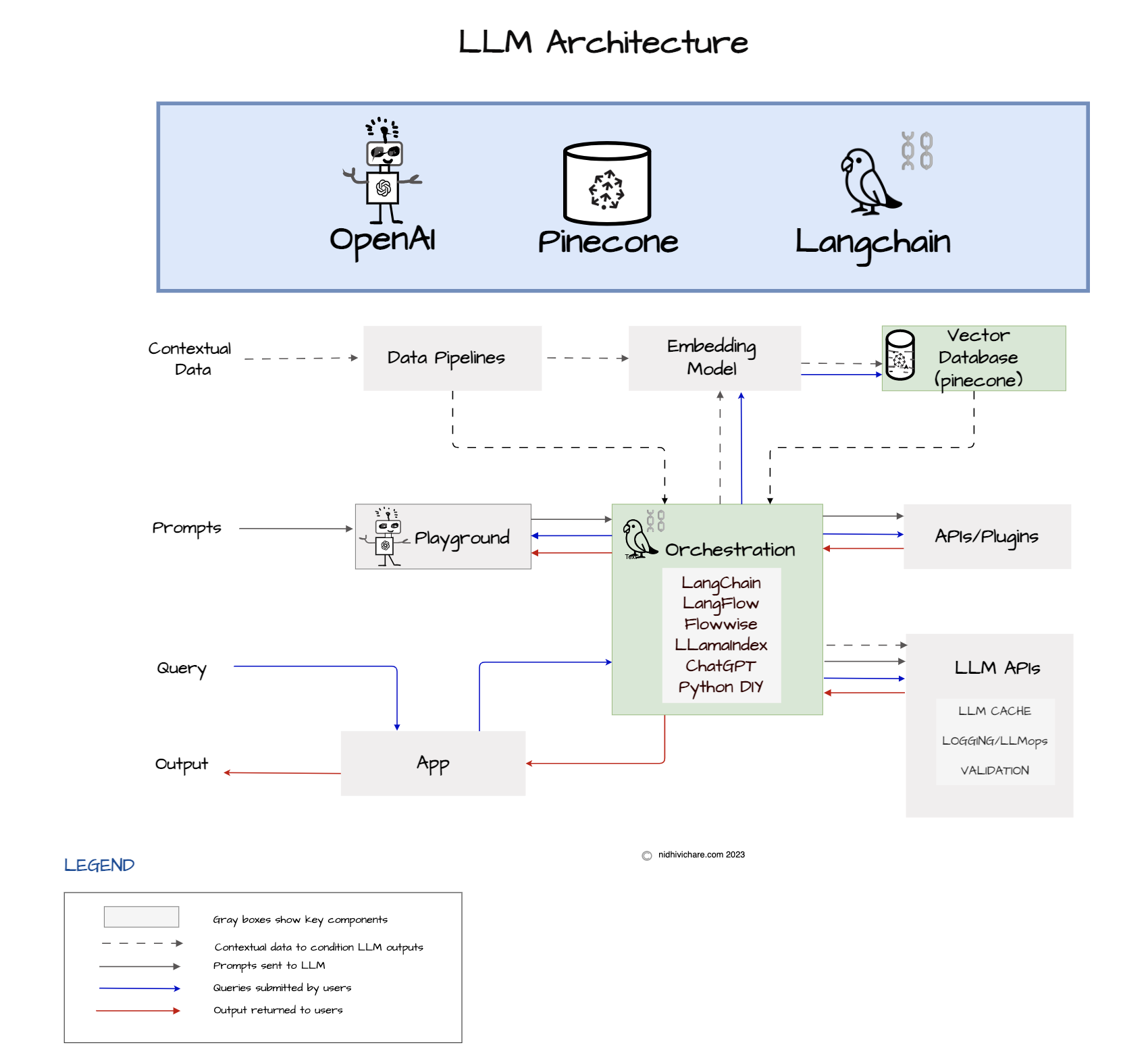
In the era of data-driven applications and artificial intelligence, converting text into numerical representations called vector embeddings has become a crucial step for various natural language processing tasks. Pinecone, a powerful service designed for storing and querying vector embeddings at scale, offers a robust infrastructure to streamline this process. In this blog post, we will explore the journey of text as it undergoes the vectorization process and how Pinecone fits into this workflow.
What are "Text to Vector Embeddings" and why do I need them?
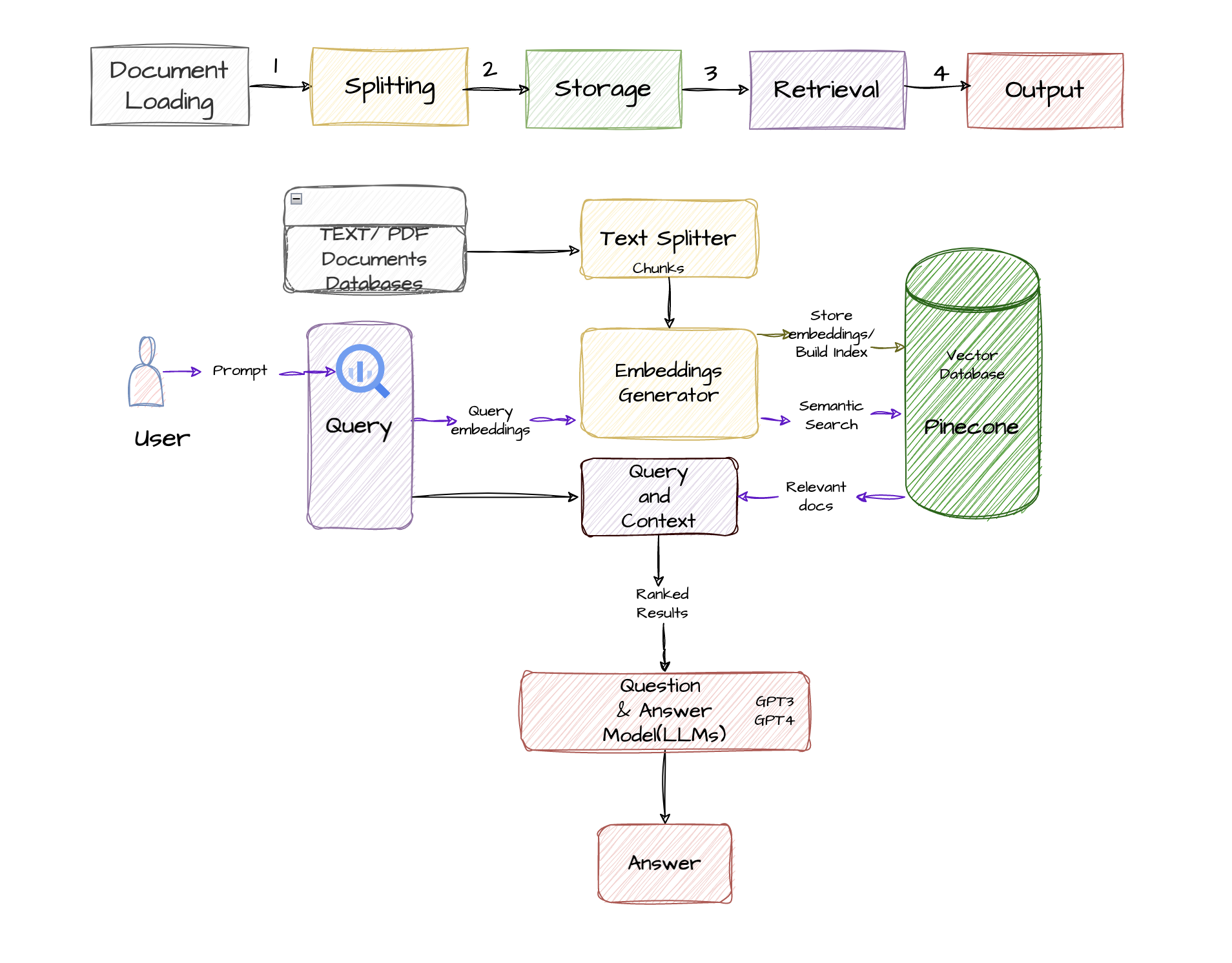
Text to vector embeddings is the process of converting textual data into numerical representations that capture semantic meaning or contextual information. Guiding developers in natural language processing, text to vector embeddings involves these steps to enable efficient processing and analysis of textual data in various NLP tasks:
- Preprocess the textual data to clean and prepare it.
- Tokenize the text into meaningful units.
- Generate vector representations such as word embeddings or sentence embeddings.
- Convert the text into numerical vectors that capture semantic meaning or contextual information.
Sequence Diagram of how to convert text to vector embeddings using Pinecone
The steps to convert text to vector embeddings using Pinecone are as follows:
- Preprocess the text data by cleaning and preparing it.
- Tokenize the text into meaningful units.
- Generate word embeddings for individual words.
- Create sentence embeddings to capture semantic meaning.
- Train custom embeddings if needed.
- Convert text to vector representations.
- Store and index vector embeddings using Pinecone.
- Perform similarity searches and retrieval with Pinecone.
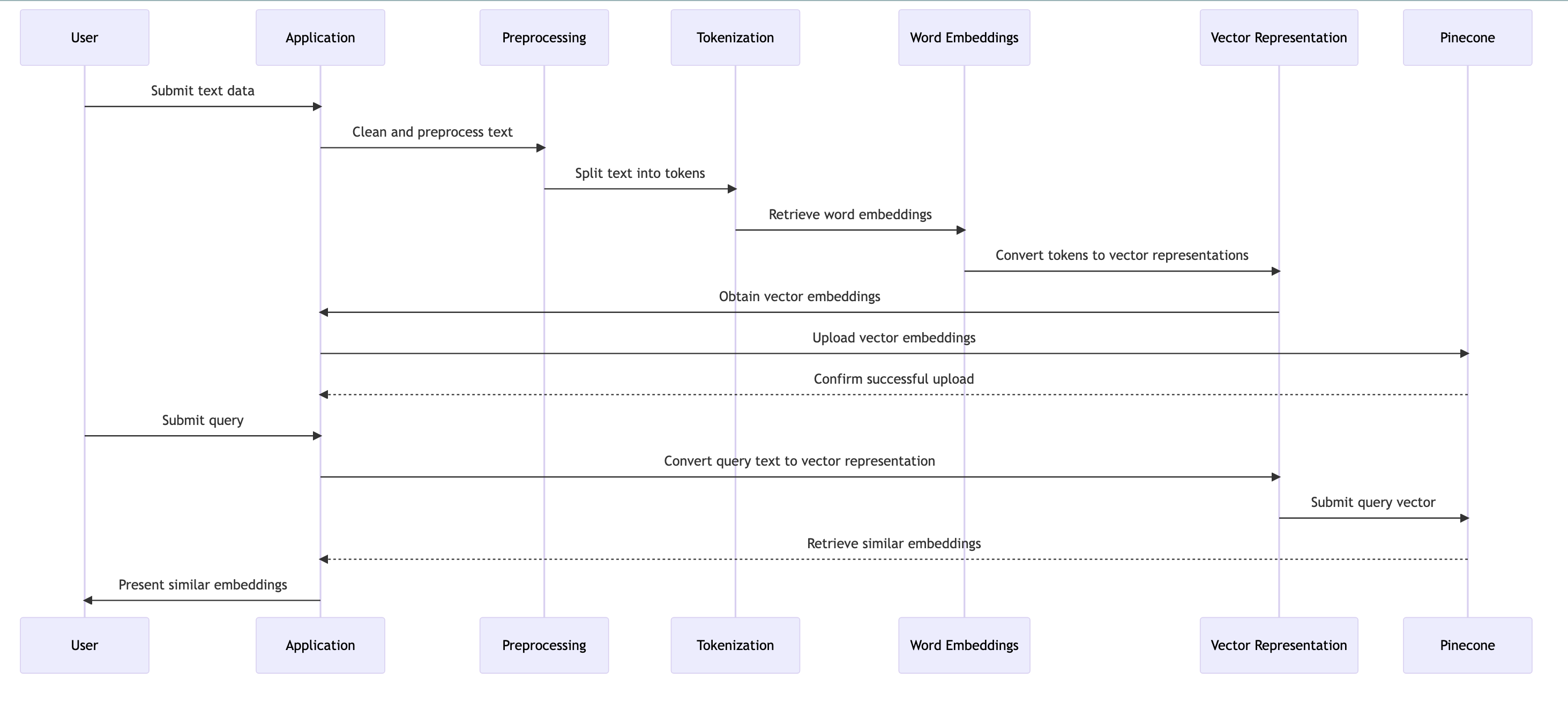
Let's Start building the QnA system using OPL(OpenAI, Pinecone and LangChain)
#### Preprocessing: Laying the Foundation Before diving into vectorization, the text data goes through a preprocessing stage. This step involves cleaning and preparing the text by removing punctuation, converting to lowercase, and handling specific requirements such as stemming or stop-word removal. Preprocessing ensures a standardized input that is ready for further analysis.
# create a file requirements.txt
openai
langchain
pinecone-client
python-dotenv
tiktoken
wikipedia
pypdf
docx2txt
python-dotenv
# install all requirements
!pip install -r requirements.txt -q
#The load_document function is a utility function that allows loading text data from different document formats such as PDF and DOCX.
# It determines the file format based on the file extension and uses the appropriate document loader to extract the text content.
import os
from langchain.document_loaders import PyPDFLoader, Docx2txtLoader
def load_document(file):
name, extension = os.path.splitext(file)
if extension == '.pdf':
print(f'Loading {file}')
loader = PyPDFLoader(file)
elif extension == '.docx':
print(f'Loading {file}')
loader = Docx2txtLoader(file)
else:
print('Document format is not supported!')
return None
data = loader.load()
return data
# wikipedia docs
#The load_from_wikipedia function is a utility function that allows loading text data from Wikipedia articles.
# It uses the WikipediaLoader class from the langchain.document_loaders module to retrieve Wikipedia content based on the
# provided query and language.
#Parameters
#query (string): The query or topic for which the Wikipedia content needs to be retrieved.
#lang (string, optional): The language code for the Wikipedia content. Defaults to 'en' (English).
#load_max_docs (int, optional): The maximum number of Wikipedia documents to load. Defaults to 2.
def load_from_wikipedia(query, lang='en', load_max_docs=2):
from langchain.document_loaders import WikipediaLoader
loader = WikipediaLoader(query=query, lang=lang, load_max_docs=load_max_docs)
data = loader.load()
return data
Tokenization: Splitting Text into Meaningful Units
To transform text into vector representations, it is necessary to break it down into smaller meaningful units called tokens. Tokenization can be performed at the word level, character level, or even using subword units, depending on the chosen approach. By splitting the text into tokens, we create the building blocks for generating vector embeddings.
#The chunk_data function is a utility function that allows splitting text data into smaller chunks or segments.
# It uses the RecursiveCharacterTextSplitter class from the langchain.text_splitter module to split the provided text data.
# Parameters
# data (string): The text data that needs to be chunked or split into smaller segments.
# chunk_size (int, optional): The desired size of each chunk in terms of the number of characters. Defaults to 256.
# The chunking process is based on the specified chunk_size parameter, which determines the size of each chunk. Adjust the chunk_size parameter according to your requirements.
# The function splits the text data into chunks without any overlap (chunk_overlap=0). If you need overlapping chunks, you can modify the chunk_overlap parameter in the RecursiveCharacterTextSplitter initialization.
def chunk_data(data, chunk_size=256):
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=0)
chunks = text_splitter.split_documents(data)
return chunks
Word Embeddings: Capturing Word-Level Context
For tasks that focus on individual words, pre-trained word embeddings come into play. Models like Word2Vec, GloVe, or FastText provide vector representations for words based on their contextual meaning within a large corpus of text. These pre-trained word embeddings capture semantic relationships and enable the creation of high-dimensional representations for each word.
#The print_embedding_cost function is a utility function that calculates and prints the embedding cost for a given list of texts.
# It utilizes the tiktoken library to encode the texts and calculate the total number of tokens.
# It then calculates the corresponding embedding cost in USD based on the total number of tokens.
# texts (list): A list of text objects or strings for which the embedding cost needs to be calculated.
# The function uses the 'text-embedding-ada-002' model for token encoding. If you want to use a different model, you can modify the model name in the encoding_for_model function call.
# The embedding cost calculation assumes a rate of 0.0004 USD per 1000 tokens (* 0.0004). You can adjust this rate according to your requirements.
def print_embedding_cost(texts):
import tiktoken
enc = tiktoken.encoding_for_model('text-embedding-ada-002')
total_tokens = sum([len(enc.encode(page.page_content)) for page in texts])
print(f'Total Tokens: {total_tokens}')
print(f'Embedding Cost in USD: {total_tokens / 1000 * 0.0004:.6f}')
Sentence Embeddings: Unveiling the Semantic Meaning In scenarios where we aim to represent entire sentences or documents, pre-trained models like BERT, Universal Sentence Encoder, or Doc2Vec step in. These models generate vector representations for complete sentences or paragraphs, capturing the semantic meaning of the text. Sentence embeddings unlock the potential for understanding the overall context and enable more comprehensive analysis.
Training your own Embeddings: Tailoring to Your Needs Alternatively, you have the option to train your own embeddings using deep learning models equipped with an embedding layer. This approach involves constructing a neural network architecture, feeding it with labeled or unlabeled text data, and optimizing the model to learn meaningful vector representations during training. Training your embeddings allows you to fine-tune the embeddings specifically for your application or domain.
Vector Representation: Converting Text to Numerical Vectors
At this stage, each token, word, or sentence is converted into a corresponding vector representation based on the chosen embedding model or approach. By assigning numerical vectors, the text data transforms into a format that can be processed by machine learning algorithms. Vector representations encode the semantic meaning or contextual information of the text, enabling efficient analysis and comparison.
Store and Index with Pinecone: Harnessing Scalable Embedding Management
With the vector embeddings generated, Pinecone comes into the picture. Pinecone is designed to handle the storage, indexing, and retrieval of vector embeddings efficiently. By leveraging Pinecone, you can store and manage your vector embeddings in a distributed and scalable manner. Pinecone's infrastructure allows for fast indexing, incremental updates, and seamless retrieval of embeddings.
#Please ensure you have the necessary libraries (pinecone, langchain.vectorstores, and langchain.embeddings.openai) installed and
# the required environment variables (PINECONE_API_KEY and PINECONE_ENV) properly set for this code to work correctly.
# The insert_or_fetch_embeddings function is a utility function that inserts or fetches embeddings using the Pinecone Vector Indexing service. It leverages the OpenAIEmbeddings class from the langchain.embeddings.openai module to generate embeddings for the provided chunks of text.
# Parameters
# index_name (string): The name of the index where the embeddings will be stored or fetched.
# chunks (list): A list of text chunks for which embeddings will be generated and inserted into the index.
# Return Value
# The function returns a Pinecone vector store object that can be used to perform operations such as similarity search and retrieval using the generated embeddings.
# The function assumes that you have set up the Pinecone API key and environment variables (PINECONE_API_KEY and PINECONE_ENV) for authentication and configuration. Ensure that you have properly set these variables in your environment.
# The function checks if the specified index_name already exists in the Pinecone service. If it does, it loads the existing embeddings into a Pinecone vector store object. If not, it creates a new index and generates embeddings for the provided chunks.
# The function assumes a dimension of 1536 for the embeddings and uses the cosine metric for similarity calculations. You can modify these parameters according to your requirements.
import pinecone
import os
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
def insert_or_fetch_embeddings(index_name, chunks):
embeddings = OpenAIEmbeddings()
pinecone.init(api_key=os.environ.get('PINECONE_API_KEY'), environment=os.environ.get('PINECONE_ENV'))
if index_name in pinecone.list_indexes():
print(f'Index {index_name} already exists. Loading embeddings ...', end='')
vector_store = Pinecone.from_existing_index(index_name, embeddings)
print(' Ok')
else:
print(f'Creating index {index_name} and embeddings ...', end='')
pinecone.create_index(index_name, dimension=1536, metric='cosine')
vector_store = Pinecone.from_documents(chunks, embeddings, index_name=index_name)
print(' Ok')
return vector_store
Pinecone Console

#delete index and cleanup as needed
import pinecone
import os
def delete_pinecone_index(index_name='all'):
pinecone.init(api_key=os.environ.get('PINECONE_API_KEY'), environment=os.environ.get('PINECONE_ENV'))
if index_name == 'all':
indexes = pinecone.list_indexes()
print('Deleting all indexes ...')
for index in indexes:
pinecone.delete_index(index)
print('All indexes deleted successfully.')
else:
print(f'Deleting index {index_name} ...', end='')
pinecone.delete_index(index_name)
print('Index deleted successfully.')
Querying with Langchain and Pinecone: Exploring Vector Similarity
Once the vector embeddings are stored and indexed in Pinecone, you can leverage its capabilities for querying. By submitting a query vector, Pinecone enables similarity searches and nearest neighbor retrieval based on vector similarity. This functionality is crucial for tasks such as recommendation systems, content matching, and clustering, where finding similar embeddings is paramount.
# The ask_and_get_answer function is a utility function that performs question-answering using a retrieval-based approach.
# It uses the provided vector_store to retrieve relevant documents based on the input question q.
# It then utilizes the ChatGPT model from OpenAI to generate an answer using the retrieved documents.
# Parameters
# vector_store (Pinecone vector store): The Pinecone vector store object containing the indexed embeddings.
# q (string): The question for which an answer needs to be generated.
# Return Value
# The function returns the generated answer as a string
# The function assumes that you have already set up the necessary retrieval and language models (vector_store, llm, retriever, chain) for the question-answering process.
# The function utilizes the RetrievalQA class from the langchain.chains module to run the question-answering process. Modify the parameters and configurations of the models according to your requirements.
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
def ask_and_get_answer(vector_store, q):
llm = ChatOpenAI(model='gpt-3.5-turbo', temperature=1)
retriever = vector_store.as_retriever(search_type='similarity', search_kwargs={'k': 3})
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
answer = chain.run(q)
return answer
def ask_with_memory(vector_store, question, chat_history=None):
if chat_history is None:
chat_history = []
llm = ChatOpenAI(temperature=1)
retriever = vector_store.as_retriever(search_type='similarity', search_kwargs={'k': 3})
crc = ConversationalRetrievalChain.from_llm(llm, retriever)
result = crc({'question': question, 'chat_history': chat_history})
chat_history.append((question, result['answer']))
return result, chat_history
Running the QnA code
#https://constitutioncenter.org/the-constitution/full-text
#create a pdf version of the above
data = load_document('constitution.pdf')
print(f'You have {len(data)} pages in your data')
print(f'There are {len(data[20].page_content)} characters in the page')
Loading constitution.pdf You have 41 pages in your data There are 1137 characters in the page
chunks = chunk_data(data)
print(len(chunks))
# print(chunks[10].page_content)
190
print_embedding_cost(chunks)
Total Tokens: 16711 Embedding Cost in USD: 0.006684
#delete_pinecone_index()
index_name = 'askadocument'
vector_store = insert_or_fetch_embeddings(index_name)
Creating index askadocument and embeddings ...Ok
q = 'What is the document about?'
answer = ask_and_get_answer(vector_store, q)
print(answer)
# The ask_questions function is a utility function that allows users to ask questions interactively and get answers in real-time. It repeatedly prompts the user for questions until the user enters "Quit" or "Exit" to end the session. For each question, it calls the ask_and_get_answer function to generate an answer using the provided vector_store and displays the answer.
# Parameters
# vector_store (Pinecone vector store): The Pinecone vector store object containing the indexed embeddings.
# Return Value
# The function does not return any value. It continuously prompts the user for questions and displays the corresponding answers until the user chooses to quit.
# The function relies on the ask_and_get_answer function to generate answers for each question. Ensure that you have defined and imported the ask_and_get_answer function properly.
# The function continuously prompts the user for questions in an interactive manner. It checks if the user has entered "Quit" or "Exit" to terminate the session and then exits after a short delay.
# Modify the prompt, question numbering, and other user interaction aspects of the function according to your requirements.
import time
def ask_questions(vector_store):
print('Write Quit or Exit to quit.')
i = 1
while True:
q = input(f'Question #{i}: ')
i += 1
if q.lower() in ['quit', 'exit']:
print('Quitting ... bye bye!')
time.sleep(2)
break
answer = ask_and_get_answer(vector_store, q)
print(f'\nAnswer: {answer}')
print(f'\n{"-" * 50}\n')
ask_questions(vector_store)
Summarization Methods
We will briefly discuss different summarization techniques, including LangChain's unique chain types: stuff, map_reduce, and refine.
- Basic Prompts
from langchain.chat_models import ChatOpenAI
from langchain.schema import(
AIMessage,
HumanMessage,
SystemMessage
)
text= """
he Infinite Game explores leadership choices, and provides guidelines to implement an "infinite game" plan. Finite mindsets focus on winning, whereas infinite mindsets develop a more significant cause than ourselves or our business. Collaborating with others, around a shared purpose, builds a better resourced, and more caring world.\
Sinek wrote The Infinite Game in 2019, as part of his own infinite game. His previous books, Start with Why, and Leaders Eat Last, lay the foundation for this, and his inspiration came from a book called Finite and Infinite Games. The author of Finite and Infinite Games, James Carse, explains how finite-minded leaders play to win, whereas infinite-minded leaders play to keep playing, ultimately for the good of the game. Building from this, Sinek evaluates finite and infinite leadership within different institutions, and he illustrates how remarkably different the results of each mindset can be.\
This summary briefly guides us through the choice to adopt a finite or infinite mindset. As the players in the game of life, this is a crucial choice that we all have to make. Whether you're in business, politics, academics, or a parent, we all need to realize that an infinite or finite mindset will impact others, long after we're gone. So if you're interested in understanding the qualities required for leadership, The Infinite Game provides crucial insights.\
"""
messages = [
SystemMessage(content='You are an expert copywriter with expertize in summarizing documents'),
HumanMessage(content=f'Please provide a short and concise summary of the following text:\n TEXT: {text}')
]
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
llm.get_num_tokens(text)
276
summary_output = llm(messages)
print(summary_output.content)
Output
"The Infinite Game" by Simon Sinek explores the concept of adopting an infinite mindset in leadership. It contrasts finite mindsets focused on winning with infinite mindsets that prioritize a greater cause. Sinek draws inspiration from James Carse's book "Finite and Infinite Games" and evaluates the impact of these mindsets in various institutions. This book offers valuable insights for anyone interested in understanding the qualities required for effective leadership.
- Prompt Templates
from langchain import PromptTemplate
from langchain.chains import LLMChain
template = '''
Write a concise and short summary of the following text:
TEXT: `{text}`
Translate the summary to {language}.
'''
prompt = PromptTemplate(
input_variables=['text', 'language'],
template=template
)
llm.get_num_tokens(prompt.format(text=text, language='English'))
297
chain = LLMChain(llm=llm, prompt=prompt)
summary = chain.run({'text': text, 'language':'hindi'})
print(summary)
Output
अनंत खेल नेतृत्व के विकल्पों की जांच करता है और "अनंत खेल" योजना को लागू करने के दिशानिर्देश प्रदान करता है। सीमित मानसिकता जीत पर केंद्रित होती है, जबकि अनंत मानसिकता हमारे या हमारे व्यापार से अधिक महत्वपूर्ण कारण को विकसित करती है। दूसरों के साथ मिलकर, एक साझा उद्देश्य के आसपास, एक बेहतर संसाधनों और संवेदनशील दुनिया का निर्माण होता है। साइनेक ने 2019 में अपने खुद के अनंत खेल के हिस्से के रूप में अनंत खेल लिखी। उनकी पिछली किताबें, स्टार्ट विथ वाई और लीडर्स ईट लास्ट, इसके नींव को रखती हैं, और उनकी प्रेरणा सीमित और अनंत खेल की एक पुस्तक से आई। सीमित और अनंत दिमाग वाले नेताओं के बारे में जेम्स कार्से, फाइनाइट एंड इनफिनाइट गेम्स के लेखक, ने बताया है कि सीमित मानसिकता वाले नेताओं की जीत के लिए खेलते हैं, जबकि अनंत मानसिकता वाले नेताओं का खेलना खेलने के लिए होता है, अंततः खेल के अच्छे के लिए। इससे आगे बढ़ते हुए, साइनेक ने विभिन्न संस्थानों में सीमित और अनंत नेतृत्व का मूल्यांकन किया है, और उन्होंने दिखाया है कि हर मानसिकता के परिणाम अत्यंत भिन्न हो सकते हैं। यह सारांश हमें सीमित या अनंत मानसिकता को अपनाने के विकल्प के माध्यम से निर्देशित करता है। जीवन के खेल के खिलाड़ी के रूप में, यह हम सभी के लिए एक महत्वपूर्ण चुनौती है जो हमें करनी होती है। चाहे आप व्यापार, राजनीति, शिक्षा या माता-पिता में हों, हमें सभी को यह समझना चाहिए कि एक अनंत या सीमित मानसिकता दूसरों पर प्रभाव डालेगी, हम चले जाने के बाद भी। तो यदि आप नेतृत्व के लिए आवश्यक गुणों को समझने में रुचि रखते हैं, तो अनंत खेल महत्वपूर्ण दर्शन प्रदान करती है।- DocumentStuffChain
The provided code demonstrates how to use a prompt template to generate a concise and short summary of a given text using a summarization chain. It utilizes various components from the langchain library, including prompt templates, chat models, and the summarize chain.
# Usage
# Ensure that you have the required dependencies installed and import the necessary modules.
# Load the input text that needs to be summarized.
# Define a prompt template with the desired structure, incorporating the text placeholder.
# Create an instance of the PromptTemplate class, specifying the input variables and the template.
# Load the summarization chain using the load_summarize_chain function, providing the chat model, chain type, prompt, and any other relevant parameters.
# Run the summarization chain on the input text using the run method.
# Access the output summary generated by the chain.
from langchain import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
with open('simonsinek.txt', encoding='utf-8') as f:
text = f.read()
# text
docs = [Document(page_content=text)]
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
template = '''Write a concise and short summary of the following text.
TEXT: `{text}`
'''
prompt = PromptTemplate(
input_variables=['text'],
template=template
)
chain = load_summarize_chain(
llm,
chain_type='stuff',
prompt=prompt,
verbose=False
)
output_summary = chain.run(docs)
print(output_summary)
Output
The text discusses the concept of the infinite game and how it applies to leadership in various institutions. It emphasizes the importance of adopting an infinite mindset, which focuses on a greater cause and long-term sustainability, rather than a finite mindset that focuses on winning and short-term gains. The text provides examples of companies that have successfully embraced an infinite mindset, such as Lego and Sweetgreen. It also highlights the key principles of leading with an infinite mindset, including advancing a just cause, building trusting teams, studying worthy rivals, preparing for existential flexibility, and demonstrating the courage to lead. The text concludes by emphasizing the need for businesses and leaders to play the infinite game in order to create a better and more sustainable world.- Map_reduce Chain
The provided code demonstrates how to perform summarization on a large text using text splitting and a map-reduce summarization chain. It utilizes components from the langchain library, including prompt templates, chat models, text splitters, and the summarize chain.
# Usage
# Ensure that you have the required dependencies installed and import the necessary modules.
# Load the input text that needs to be summarized.
# Create an instance of the chat model (ChatOpenAI in this case) for generating summaries.
# Determine the number of tokens in the input text using the get_num_tokens method of the chat model.
# Configure the text splitting process by creating an instance of RecursiveCharacterTextSplitter, specifying the desired chunk_size and chunk_overlap.
# Split the input text into smaller chunks using the create_documents method of the text splitter.
# Obtain the number of chunks generated.
# Load the summarization chain using the load_summarize_chain function, providing the chat model, chain type, and any other relevant parameters.
# Run the summarization chain on the chunks using the run method.
# Access the output summary generated by the chain.
from langchain import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
with open('simonsinek.txt', encoding='utf-8') as f:
text = f.read()
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
num_tokens = llm.get_num_tokens(text)
print(num_tokens) # 3435
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=50)
chunks = text_splitter.create_documents([text])
num_chunks = len(chunks)
print(num_chunks) # 2
chain = load_summarize_chain(llm, chain_type='map_reduce', verbose=False)
output_summary = chain.run(chunks)
Output
"The Infinite Game" by Simon Sinek explores the concept of adopting an infinite mindset in leadership, prioritizing a greater cause and long-term sustainability. Sinek provides guidelines for implementing an infinite game plan, emphasizing the importance of clarity of purpose and criticizing the current form of capitalism. The article suggests that by adopting an infinite mindset, leaders can create sustainable companies that make a positive difference in the world. print(output_summary)
chain.llm_chain.prompt.template
chain.combine_document_chain.llm_chain.prompt.template
'Write a concise summary of the following:\n\n\n"{text}"\n\n\nCONCISE SUMMARY:'
Custom Prompts
map_prompt = '''
Write a short and concise summary of the following:
Text: `{text}`
CONCISE SUMMARY:
'''
map_prompt_template = PromptTemplate(
input_variables=['text'],
template=map_prompt
)
combine_prompt = '''
Write a concise summary of the following text that covers the key points.
Add a title to the summary.
Start your summary with an INTRODUCTION PARAGRAPH that gives an overview of the topic FOLLOWED
by BULLET POINTS if possible AND end the summary with a CONCLUSION PHRASE.
Text: `{text}`
'''
combine_prompt_template = PromptTemplate(template=combine_prompt, input_variables=['text'])
summary_chain = load_summarize_chain(
llm=llm,
chain_type='map_reduce',
map_prompt=map_prompt_template,
combine_prompt=combine_prompt_template,
verbose=False
)
output = summary_chain.run(chunks)
print(output)
Output
Title: "The Infinite Game" by Simon Sinek: Embracing an Infinite Mindset in Leadership
Introduction:
"The Infinite Game" by Simon Sinek explores the concept of adopting an infinite mindset in leadership, contrasting it with the finite-minded approach. Sinek emphasizes the importance of prioritizing a greater cause and long-term sustainability over short-term gains.
Key Points:
- Finite-minded leaders focus on winning and short-term gains, while infinite-minded leaders prioritize a greater cause and long-term sustainability.
- Guidelines for implementing an infinite game plan include advancing a just cause, building trusting teams, studying worthy rivals, preparing for flexibility, and demonstrating courage.
- Clarity of purpose is crucial, and the current form of capitalism is criticized for prioritizing profits over employee well-being and long-term success.
- Examples of organizations successfully embracing an infinite mindset include Lego and Patagonia.
Conclusion:
"The Infinite Game" highlights the importance of business leaders focusing on a Just Cause and having a clear vision. It emphasizes the need for building trusting teams, studying rivals, embracing existential flexibility, and demonstrating courage. By challenging convention and creating lasting companies, leaders can contribute to a better world.
- Refine Chain The provided code demonstrates a complete workflow for document loading, text splitting, and summarization using a refinement-based approach. It utilizes components from the langchain library, including chat models, prompt templates, text splitters, document loaders, and the summarize chain.
# Ensure that you have the required dependencies installed and import the necessary modules.
# Load the document using the desired document loader (in this case, UnstructuredPDFLoader).
# Split the loaded document into smaller chunks using the RecursiveCharacterTextSplitter with specified chunk_size and chunk_overlap parameters.
# Determine the number of chunks generated.
# Create an instance of the chat model (ChatOpenAI in this case) for generating summaries.
# Define a function (print_embedding_cost in this case) to calculate and print the embedding cost for the chunks.
# Calculate and print the embedding cost using the defined function.
# Load the summarization chain using the load_summarize_chain function, providing the chat model, chain type, and any other relevant parameters.
# Run the summarization chain on the chunks, producing an initial summary.
# Print the initial summary.
# Define prompt templates for refinement-based summarization, including an initial prompt template and a refinement prompt template.
# Load a new summarization chain using the load_summarize_chain function, specifying the prompt templates and other relevant parameters.
# Run the new summarization chain on the chunks, producing a refined summary.
# Print the refined summary.
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import UnstructuredPDFLoader
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv(), override=True)
!pip install unstructured -q
!pip install pdf2image
loader = UnstructuredPDFLoader('data-catalogs.pdf')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
num_chunks = len(chunks)
print(num_chunks)
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
def print_embedding_cost(texts):
import tiktoken
enc = tiktoken.encoding_for_model('gpt-3.5-turbo')
total_tokens = sum([len(enc.encode(page.page_content)) for page in texts])
print(f'Total Tokens: {total_tokens}')
print(f'Embedding Cost in USD: {total_tokens / 1000 * 0.002:.6f}')
print_embedding_cost(chunks)
chain = load_summarize_chain(
llm=llm,
chain_type='refine',
verbose=True
)
output_summary = chain.run(chunks)
print(output_summary)
prompt_template = """Write a concise summary of the following extracting the key information:
Text: `{text}`
CONCISE SUMMARY:"""
initial_prompt = PromptTemplate(template=prompt_template, input_variables=['text'])
refine_template = '''
Your job is to produce a final summary.
I have provided an existing summary up to a certain point: {existing_answer}.
Please refine the existing summary with some more context below.
------------
{text}
------------
Start the final summary with an INTRODUCTION PARAGRAPH that gives an overview of the topic FOLLOWED
by BULLET POINTS if possible AND end the summary with a CONCLUSION PHRASE.
'''
refine_prompt = PromptTemplate(
template=refine_template,
input_variables=['existing_answer', 'text']
)
chain = load_summarize_chain(
llm=llm,
chain_type='refine',
question_prompt=initial_prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=False
)
output_summary = chain.run(chunks)
print(output_summary)
Output
Introduction:
The demand for data catalogs is increasing as organizations struggle to manage and analyze diverse and distributed data assets. Data and analytics leaders are advised to adopt machine learning (ML)-augmented data catalogs as part of their data management strategy. Implementing data catalogs without a strategic plan can lead to metadata silos. Data catalogs offer a solution to inventory and classify data assets, but selecting the right solution can be challenging. Without a comprehensive strategy, organizations may struggle to manage and monetize data assets and comply with regulations. By 2021, organizations with curated data catalogs will realize twice the business value compared to those without. Over 80% of data lake projects will fail due to difficulties in finding and curating data. Traditional IT-led data catalog projects without ML assistance will fail to be delivered on time. ML-augmented data catalogs simplify metadata management tasks and reduce time to insight. They assist with discovering metadata, understanding and enriching data, contributing and governing data, and consuming data. Modern ML-enabled data catalogs allow for a crowdsourced model to be developed, enabling users to rate datasets and tag risky attributes. Data catalogs also help create a trust-based governance model and provide a graphical representation of data lineage. Business users can consume data through embedded query editors and REST-based APIs. ML-augmented data catalogs have evolved to collect and share all forms of metadata, enabling automation of data management and integration tasks. There are various types of data catalog tools available, including stand-alone data catalogs and broader metadata management tools with data catalog capabilities. Organizations should identify use cases for metadata management and inventory all forms of metadata to improve data management activities. The abundance of data catalog tool choices can create confusion, so selecting the most appropriate tool category is crucial. Some metadata management tools are simply being rebranded as data catalogs, so organizations need to be careful when selecting a vendor. Data integration and data virtualization tools, data lake enablement tools, data preparation tools, and modern analytics/BI and data science platforms are embedding data catalog capabilities. Cloud infrastructure providers also offer data catalogs for their environments.
Bullet Points:
- Passive metadata is static in nature and requires manual updates, while active metadata provides continuous access, analysis, and feedback on all metadata parameters.
- Customer interest in data catalogs has increased significantly, making it a lucrative market for vendors.
- Organizations should consider ML-augmented data catalogs to simplify metadata management tasks and reduce time to insight.
- ML-enabled data catalogs allow for a crowdsourced model, enabling users to rate datasets and tag risky attributes.
- Data catalogs help create a trust-based governance model and provide a graphical representation of data lineage.
- Various types of data catalog tools are available, including stand-alone data catalogs and broader metadata management tools with data catalog capabilities.
- Organizations should identify use cases for metadata management and inventory all forms of metadata to improve data management activities.
- Careful consideration is needed when selecting a vendor, as some metadata management tools are simply rebranded as data catalogs.
- Data integration and data virtualization tools, data lake enablement tools, data preparation tools, and modern analytics/BI and data science platforms are embedding data catalog capabilities.
- Cloud infrastructure providers also offer data catalogs for their environments.
Conclusion:
In conclusion, adopting ML-augmented data catalogs and selecting the right tool category are essential for organizations to effectively manage and analyze their data assets. The increasing demand for data catalogs and the potential business value they offer make it a lucrative market for vendors. Organizations should carefully consider their metadata management needs and select a data catalog tool that best suits their requirements.
- LangChain Agents
The provided code demonstrates how to use the langchain library to initialize an agent that can provide a short summary of a specific topic using zero-shot reaction and Wikipedia information retrieval. It utilizes components such as chat models, agents, and utility functions from the langchain library.
# Usage
# Ensure that you have the required dependencies installed and import the necessary modules.
# Create an instance of the chat model (ChatOpenAI in this case) to provide language generation capabilities.
# Create an instance of the WikipediaAPIWrapper utility class to retrieve information from Wikipedia.
# Define a list of Tool objects, where each object represents a specific tool or information source that the agent can use.
# Initialize the agent using the initialize_agent function, providing the list of tools, chat model, and agent type.
# Run the agent by calling the run method of the agent executor, passing the query or topic for which you want a short summary.
# Access the output generated by the agent.
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, Tool
from langchain.utilities import WikipediaAPIWrapper
llm = ChatOpenAI(temperature=0, model_name='gpt-3.5-turbo')
wikipedia = WikipediaAPIWrapper()
tools = [
Tool(
name="Wikipedia",
func=wikipedia.run,
description="Useful for when you need to get information from Wikipedia about a single topic"
)
]
agent_executor = initialize_agent(tools, llm, agent='zero-shot-react-description', verbose=True)
output = agent_executor.run('Can you please provide a short summary of Simon Sinek?')
print(output)
Output
> Entering new chain...
I should use Wikipedia to get information about Simon Sinek.
Action: Wikipedia
Action Input: Simon Sinek
Observation: Page: Simon Sinek
Summary: Simon Oliver Sinek (born October 9, 1973) is a British-born American author and inspirational speaker. He is the author of five books, including Start With Why (2009) and The Infinite Game (2019).
Page: Sinek
Summary: Sinek is a surname. Notable people with the surname include:
Charles Sinek (born 1968), American ice dancer
Simon Sinek (born 1973), British-American author
Page: The Infinite Game
Summary: The Infinite Game is a 2019 book by Simon Sinek, applying ideas from James P. Carse's similarly titled book, Finite and Infinite Games to topics of business and leadership.The book is based on Carse's distinction between two types of games: finite games and infinite games. As Sinek explains, finite games (e.g. chess and football) are played with the goal of getting to the end of the game and winning, while following static rules. Every game has a beginning, middle, and end, and a final winner is distinctly recognizable. In contrast, infinite games (e.g. business and politics) are played for the purpose of continuing play rather than to win. Sinek claims that leaders who embrace an infinite mindset, aligned with infinite play, will build stronger, more innovative, inspiring, resilient organizations, though these benefits may accrue over larger timescales than benefits associated with a finite mindset.
Thought:I now know the final answer.
Final Answer: Simon Sinek is a British-born American author and inspirational speaker. He is the author of five books, including "Start With Why" and "The Infinite Game."
> Finished chain.
output:
Simon Sinek is a British-born American author and inspirational speaker. He is the author of five books, including "Start With Why" and "The Infinite Game."
Conclusion
Integrating Pinecone, a high-performance vector database, with LangChain, a framework for LLM-powered applications, enables the development of sophisticated applications. This integration adds "long-term memory" to LLMs, enhancing autonomous agents, chatbots, and question answering systems by leveraging scalable, real-time recommendation and search systems based on vector similarity search. The process of converting text to vector embeddings involves several stages, including preprocessing, tokenization, utilizing pre-trained word and sentence embeddings, or training your own embeddings. Pinecone plays a vital role in this journey by offering a scalable infrastructure for storing, indexing, and querying vector embeddings. By leveraging Pinecone's capabilities, developers can efficiently manage and retrieve embeddings, enabling tasks such as recommendation systems and content matching.
Further Reading
🔗 Read more about Pinecone here
🔗 Read more about Langchain here