Debezium - A Primer
Debezium is a powerful platform that can be used in a variety of use cases where real-time data capture and streaming are required. Its flexibility, scalability, and extensibility make it a popular choice among organizations that need to build real-time data pipelines and microservices-based architectures.

 Credit: Unsplash
Credit: Unsplash
DEBEZIUM - An Overview
Debezium is an open-source platform that allows for real-time data streaming and change data capture (CDC) from databases, message brokers, and other sources. Debezium is a powerful platform that can be used in a variety of use cases where real-time data capture and streaming are required. Its flexibility, scalability, and extensibility make it a popular choice among organizations that need to build real-time data pipelines and microservices-based architectures.
Use Cases
-
Real-time data integration: Debezium makes it easy to capture changes in databases and stream them in real-time to other systems, such as data lakes, data warehouses, and analytics platforms. This allows organizations to build real-time data pipelines that can be used for a variety of use cases, including real-time reporting, machine learning, and fraud detection.
-
Microservices-based architectures: Debezium can be used as a key component in microservices-based architectures. By capturing changes in databases and streaming them to other microservices, Debezium enables loosely coupled architectures that can scale horizontally and handle high volumes of data.
-
Data replication: Debezium can be used for replicating data between databases, making it easy to keep data in sync across different systems. This is particularly useful for organizations that have multiple databases that need to be kept in sync.
-
Change data capture (CDC): Debezium is primarily used for CDC, which is the process of capturing changes made to a database and making those changes available in real-time to other systems. CDC can be used for a variety of use cases, including auditing, compliance, and data integration.
Here's a brief overview of how Debezium works
Debezium connectors: Debezium includes a set of connectors that capture the changes in the data sources and send them to the Debezium engine for processing. These connectors can monitor different data sources such as MySQL, PostgreSQL, MongoDB, Cassandra, and SQL Server.
Change Data Capture (CDC): Change data capture is the process of detecting and capturing changes made to data in a database. CDC is used to identify new, changed, and deleted data in a database.
Debezium Engine: The Debezium engine is responsible for processing the data captured by the connectors. It transforms the raw change data into a standard format that can be understood by downstream systems, such as Apache Kafka.
Message Broker: Debezium can stream data changes to Apache Kafka, which acts as a message broker. Kafka is a high-throughput, distributed messaging system that can store and stream large volumes of data.
Data Consumers: Data consumers are applications or systems that consume the data streamed by Debezium from the message broker. These consumers can use the data for various purposes, such as real-time analytics, ETL processes, or data warehousing.
Overall, Debezium makes it easy to capture and stream changes in data from various sources and process them in real-time. The platform is highly scalable and can handle large volumes of data with low latency, making it ideal for use in modern data architectures.
Architecture
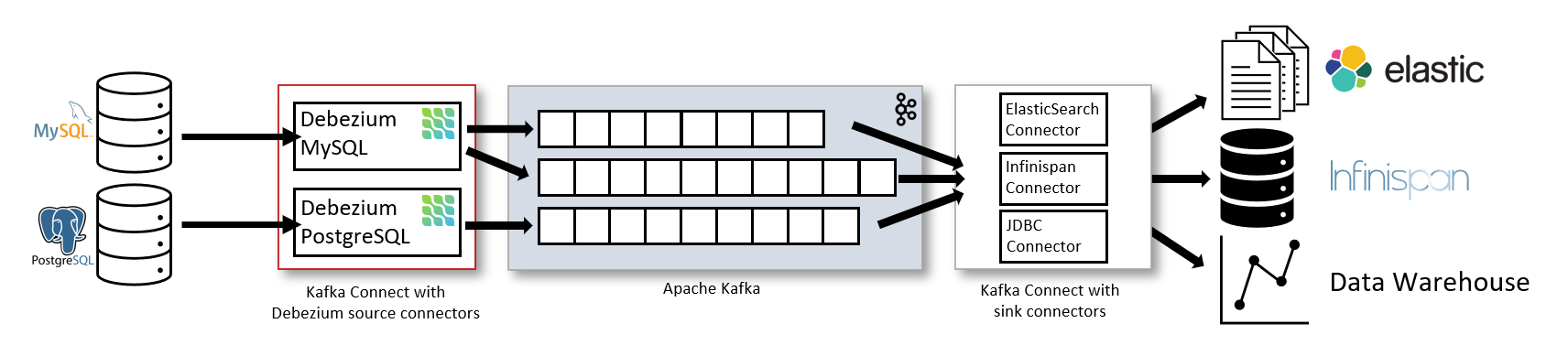 Credit: Debezium
Credit: Debezium
In this diagram, you can see the various components of the Debezium architecture, including the connectors, Kafka, schema registry, and consumers. The connectors capture changes from the source databases and publish them to Kafka, where they can be consumed by other applications. The schema registry manages the schema of the messages published to Kafka, ensuring that they are compatible across different applications. Finally, the consumers consume the messages published to Kafka and use them for various purposes, such as analytics, reporting, and machine learning.
Deployment
Deploying Debezium involves several steps, including setting up the environment, configuring the connectors, and starting the engine. Here's a high-level overview of how to deploy Debezium:
Set up the environment: You need to have a running instance of Apache Kafka and a compatible database system, such as MySQL or PostgreSQL, to use with Debezium. You also need to download and install the Debezium platform.
Configure the connector: Debezium connectors are used to capture data changes from the database and send them to the message broker. You need to configure the connector by specifying the connection details, tables to be monitored, and other settings.
Start the Debezium engine: The Debezium engine is responsible for processing the change data captured by the connector. You need to start the engine by specifying the configuration file and the connector.
Verify the data: Once the Debezium engine is running, you can verify that the data changes are being streamed to Kafka by using a Kafka consumer to read the messages.
Here's an example of how to deploy Debezium using Docker:
-
Install Docker on your machine.
-
Download the Debezium Docker image from the Docker Hub registry:
docker pull debezium/connect:1.6
- Start the Debezium container with the required environment variables and mount the configuration file:
docker run -it --rm --name debezium -p 8083:8083 -v /path/to/config:/config debezium/connect:1.6
- Configure the connector by creating a JSON file in the mounted directory:
{
"name": "my-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "user",
"database.password": "password",
"database.server.id": "1",
"database.server.name": "mydb",
"table.include.list": "mydb.mytable"
}
}
- Start the Debezium engine by posting the connector configuration to the REST API:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d @/path/to/config/my-connector.json
- Verify that the data changes are being streamed to Kafka by using a Kafka consumer:
kafka-console-consumer --bootstrap-server localhost:9092 --topic mydb.mytable
That's a basic overview of how to deploy Debezium. The exact steps may vary depending on your environment and use case.
Time Travel Feature
Debezium has a feature called "time-travel" that allows you to query the historical data of a database as it appeared at a particular point in time. This is made possible by the way that Debezium captures and stores the changes made to the database.
When a Debezium connector captures a change in the database, it records not only the new data but also the previous state of the data before the change was made. This is known as "change data capture" (CDC). Debezium stores this historical data in Kafka topics, where it can be accessed and queried by downstream consumers.
By consuming these Kafka topics, you can perform queries that allow you to see how the data appeared at a specific point in time. This is known as "time-travel" because you can "go back in time" and see the state of the data at a specific moment.
To enable time-travel in Debezium, you need to configure the connector to capture the full history of the data changes by setting the "snapshot.mode" property to "snapshot" and the "snapshot.isolation.mode" property to "read_committed". This ensures that Debezium captures all the changes made to the database, including those that occurred before the connector was started.
Once you have the historical data captured in Kafka topics, you can query it using tools like Kafka Streams or Apache Flink to perform time-travel queries. These queries can allow you to see how the data appeared at different points in time, which can be useful for debugging, auditing, and other purposes.
Capturing change data at the table level
Debezium supports capturing change data at the table level. This means that you can configure the Debezium connector to capture changes for specific tables in your database, rather than capturing changes for the entire database.
This can be useful in situations where you are only interested in changes made to specific tables, or if capturing changes for the entire database would result in too much data being captured.
To configure table-level CDC in Debezium, you can use the "table.include.list" or "table.whitelist" configuration property when setting up the connector. These properties allow you to specify the names of the tables that you want to capture changes for.
For example, if you only want to capture changes for a table named "orders" in a MySQL database, you could configure the Debezium MySQL connector like this:
{
"name": "my-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "user",
"database.password": "password",
"database.server.id": "1",
"database.server.name": "mydb",
"table.include.list": "mydb.orders"
}
}
With this configuration, the Debezium connector will only capture changes made to the "orders" table in the "mydb" database.
It's worth noting that Debezium also supports filtering changes based on other criteria, such as the database schema, column names, or the type of change (inserts, updates, deletes). This gives you a lot of flexibility in how you configure the connector to capture change data.
Debezium integration with airflow
Debezium can work with Apache Airflow to enable real-time data streaming and processing. Airflow is a popular open-source workflow management system that allows you to define, schedule, and monitor data processing pipelines.
You can use Debezium to capture changes in your database and publish them to Kafka topics, which can then be consumed by Apache Airflow to trigger workflows or perform other processing tasks.
Here's an example of how you could use Debezium with Apache Airflow:
Set up Debezium to capture changes in your database and publish them to Kafka topics. Set up a Kafka consumer in Airflow that subscribes to the Kafka topics published by Debezium. Define an Airflow DAG that triggers whenever new data is published to the Kafka topics. Within the DAG, define tasks that process the new data in some way, such as loading it into a data warehouse or running machine learning models on it. Monitor the DAG and the tasks using the Airflow UI or command-line tools. By combining Debezium and Airflow, you can create a powerful real-time data processing pipeline that can scale to handle large volumes of data. This can be useful in situations where you need to perform data analysis or processing in real-time, such as fraud detection or recommendation systems.
Change Data Capture
Set up Postgres CDC (Change Data Capture) using the Write-Ahead Log (WAL) method with Debezium
Perform the following steps
-
Install and configure PostgreSQL
-
If you haven't already, you'll need to install and configure PostgreSQL on your system. You can download PostgreSQL from the official website and follow the installation instructions for your operating system.
3.Install and configure Kafka
4.Next, you'll need to install and configure Kafka, which is used by Debezium to publish the captured changes.
- You can download Kafka from the Apache Kafka website and follow the installation instructions for your operating system.
6.Install and configure Debezium
7.Next, you'll need to install and configure Debezium, which is used to capture the changes from the PostgreSQL WAL and publish them to Kafka.
-
You can download Debezium from the official website and follow the installation instructions for your operating system.
-
Configure the Debezium PostgreSQL connector
-
Once you have Debezium installed, you'll need to configure the PostgreSQL connector to capture the changes from the WAL and publish them to Kafka.
Here's an example of how to configure the Debezium PostgreSQL connector:
name=postgres-connector
connector.class=io.debezium.connector.postgresql.PostgresConnector
database.hostname=localhost
database.port=5432
database.user=postgres
database.password=password
database.dbname=mydb
slot.name=debezium
plugin.name=wal2json
key.converter=io.confluent.connect.avro.AvroConverter
key.converter.schema.registry.url=http://localhost:8081
value.converter=io.confluent.connect.avro.AvroConverter
value.converter.schema.registry.url=http://localhost:8081
-
This configuration sets up the Debezium PostgreSQL connector to capture the changes from the "mydb" database and publish them to Kafka. It also specifies the key and value converters to use for encoding the messages in Avro format.
-
Start the Debezium connector
12.Once you have the connector configured, you can start it using the Kafka Connect API. You can do this by running the following command:
$ ./bin/connect-standalone.sh config/connect-standalone.properties config/postgres-connector.properties
-
This command starts the Kafka Connect API and tells it to use the Debezium PostgreSQL connector that you configured in the "postgres-connector.properties" file.
-
Consume the Kafka topic Finally, you can consume the Kafka topic where the connector is publishing its changes using a Kafka consumer. You can do this using the Kafka command-line tools or any other tool that supports Kafka, such as Apache Spark or Apache Flink.
For example, you can use the following command to consume the Kafka topic and print the messages to the console:
$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mydb.public.customers
- This command starts a Kafka consumer that subscribes to the "mydb.public.customers" topic and prints the messages to the console as they arrive.
That's it! With these steps, you can set up Postgres CDC using the WAL method with Debezium.
In Summary
Debezium, PostgreSQL, and Snowflake are three popular technologies that are commonly used together for real-time data integration and analytics. Here's a summary of their architecture and use case:
Debezium: Debezium is an open-source distributed platform for capturing and streaming changes in databases. It uses a microservices-based architecture that includes connectors for capturing changes in databases, Kafka for publishing changes, and consumers for consuming changes. Debezium can be deployed in a variety of ways and is designed to be flexible, scalable, and extensible.
PostgreSQL: PostgreSQL is a powerful open-source relational database that is widely used in production environments. It supports ACID transactions, SQL, and JSON, making it a versatile database for a variety of use cases.
Snowflake: Snowflake is a cloud-based data warehousing platform that enables organizations to store, analyze, and share large amounts of data. It is designed to be highly scalable and performant, and it supports SQL and various programming languages.
Use case
One common use case for Debezium, PostgreSQL, and Snowflake is real-time data integration and analytics. Here's how it works:
Debezium is used to capture changes made to a PostgreSQL database in real-time.
The changes are streamed to Kafka, where they can be consumed by Snowflake.
Snowflake can then process and analyze the changes in real-time, using SQL and other programming languages.
The results of the analysis can be stored in Snowflake and used for various purposes, such as reporting, machine learning, and data visualization.
Overall, the architecture of Debezium, PostgreSQL, and Snowflake is designed to be flexible, scalable, and performant, making it a powerful platform for real-time data integration and analytics.
About the author
Nidhi Vichare is an enterprise AI and data executive, platform architect, and author of The Meaning Layer. She writes about enterprise AI strategy, data architecture, causal measurement, AI ROI, agentic systems, and modern leadership for senior data and AI leaders.